Llama2 website https://ai.meta.com/llama/
Hi friend, I would like to introduce a new LLM, which was released from Meta on July 18,2023. It is called “Llama2”. I have some experiments with this model. Let us start!
1. What is Llama2?
“Llama2” is language model from Meta AI. Many researchers are very excited because it is a open source and available for commercial usage. Its specs are explained in the table below.

Llama2 website https://ai.meta.com/llama/
2. Let us extract information from the article in English
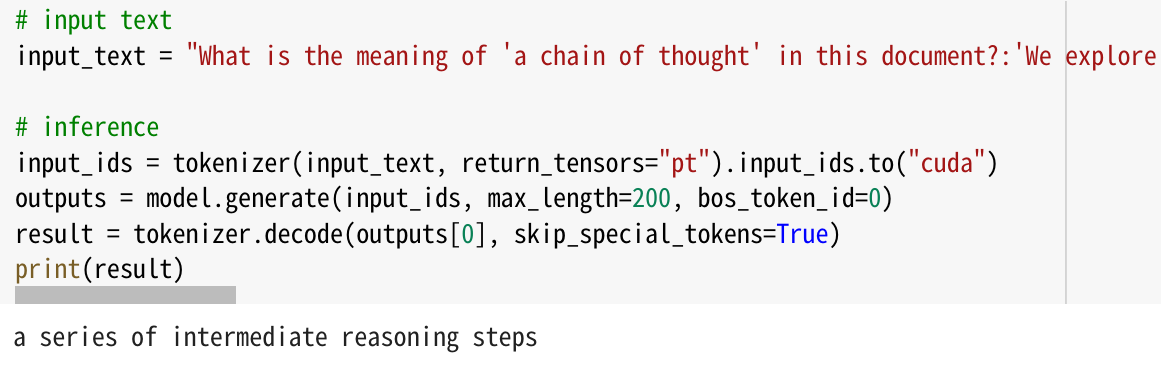
I want to perform a small experiment to extract information from text.
sentiment
root cause of the sentiment
name of product
name of makers of product
I made my prompt and fiction story in the mail. Then run Llama2 13B chat. Here are the results


Woh, looks good! I can obtain the information I need from text. Unfortunately the model cannot output it in Japanese.
3. Let us see how it works against Japanese sentences
Next, I would like to apply the same prompt against Japanese sentences here.


Woh, looks good, too! Although the model cannot output it in Japanese, either.
4. Llama2 has a great potential for AI applications in the future!
Today I found that Llama2 works in English very well. When we want to minimize running costs for AI applications or keep secret/confidential data within our organization, this model can be a good candidate for AI models in our applications. It is great to have many choices of LLMs in addition to proprietary models, such as ChatGPT.
I want to mention a great repo on GitHub. It makes it easier to compare many open source LLMs, It is a strong recommendation for everyone who is interested in LLMs. Thanks camenduru!
Thanks for your attention! would like to follow the progress of Llama2 and share it with you soon. Stay tuned!
Copyright © 2023 Toshifumi Kuga All right reserved
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.