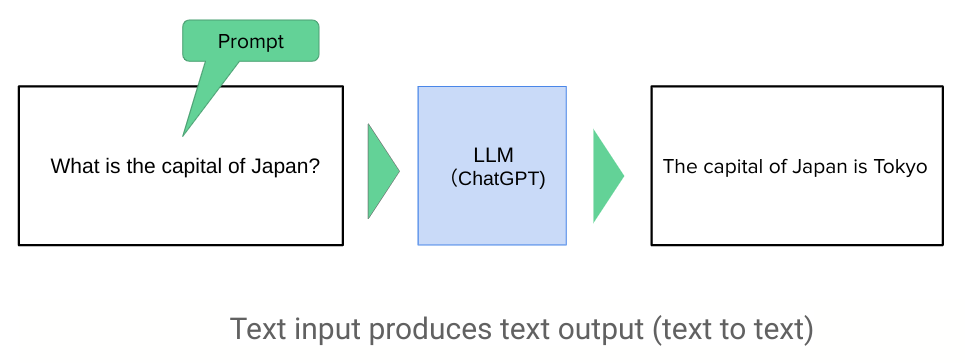
Today, we'll be diving into Google DeepMind's recently announced compact generative AI model, "Gemma2-2B" (1), and running a simple demo. Gemma is an open-source library. While medium-sized models with 70B and 9B parameters are already available, this latest release boasts a significantly smaller 2B parameter model. It promises remarkable performance despite its size, generating considerable excitement. Let's take a closer look.
1. Remarkable Fundamental Performance
Despite its compact size, the Gemma model exhibits impressive performance, as detailed below. Surpassing GPT3.5 is a feat unimaginable just a year ago. The rapid advancements in open-source models continue to amaze.

Google's website describes it as follows (1):
""This lightweight model produces outsized results by learning from larger models through distillation. In fact, Gemma 2 2B surpasses all GPT-3.5 models on the Chatbot Arena, demonstrating its exceptional conversational AI abilities.
The "distillation" technique mentioned here is key to enhancing the performance of smaller models. It's employed not only in Gemma but also in Llama3 and various other small models, making it a concept worth remembering. With the performance of a 2B parameter model reaching such heights, it's tempting to explore its capabilities. Let's move on to the demo.
2. Performance Check with a News Article Classification Task
For this demo, we'll tackle the task of classifying Japanese articles from the publicly available Livedoor-news dataset (2) into five genres. We'll fine-tune the Gemma2-2B model and evaluate its classification accuracy. Since we're using Japanese articles, this will also assess its multilingual capabilities. Let's get started!
The following article is an example from the validation data. The model's task is to identify this article as belonging to the sports category.

Example of validation data
Specifically, each article is categorized into one of the following categories. The goal of today's demo is to improve the accuracy of this classification.
'kaden-channel' (Electronics)
'topic-news' (General News)
'sports-watch' (Sports)
'it-life-hack' (IT/Life Hacks)
'movie-enter' (Movies/Entertainment)
We prepared 100 samples for training data and 1000 samples for validation data. We'll apply fine-tuning using the impressive quantization tool Unsloth, and the data will be in the Alpaca format. For details, please refer to this link (3).
Without extensive tuning, we achieved an accuracy of 81.5%, as shown below. Considering the small training dataset of only 100 samples, this is an impressive result. With further optimization, the accuracy could likely be improved. It's hard to believe this performance comes from a model with only 2B parameters. Its ability to handle Japanese text is also commendable. The notebook used for the demo can be found here.

3. Limitless Potential Applications
With such high performance in a small model, the possibility of implementation on devices like smartphones, previously deemed impractical, becomes a reality. It also opens doors for applications where cost and computational speed were prohibitive. It seems particularly well-suited for customer service applications requiring real-time responses. Additionally, it could be deployed in developing countries where the cost of using frontier models like GPT4 has been a barrier. The future possibilities are truly exciting.
So, what did you think? The Gemma2-2B model can run on Google Colab's free T4 GPU, making it a valuable asset for startups like ours. It's truly remarkable. The small yet powerful Gemma2-2B model is poised for widespread adoption. At ToshiStats, we're committed to developing tuning techniques to maximize the benefits of open-source libraries. We'll be sharing more on this blog in the future. That's all for today. Stay tuned!
(1) Smaller, Safer, More Transparent: Advancing Responsible AI with Gemma
(2) Livedoor-news Japanese articles
(3) Alpaca + Gemma2-2B full example.ipynb
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.