
I’ve been using Opus 4.6 for coding lately, but I've realized that the costs can really add up when running it via API. This led me to think that for tasks where absolute peak precision isn't the only priority, a more budget-friendly model would be a better fit. Right on cue, Google announced the gemini-3.1-flash-lite-preview—a model built for speed and affordability (1). I decided to put it to the test immediately.
1. The Perfect Balance of Speed, Cost, and Performance
The Flash-Lite series is the most affordable tier in the Gemini lineup. It’s likely the engine behind many of Google’s own internal services. Speed, in particular, seems to be its standout feature.

When compared to its rivals, the processing speed is remarkably fast. Its cost-efficiency is equally impressive: at $0.25 per 1 million input tokens, it is poised to be a powerhouse for tasks involving massive amounts of data. For a startup like ours, this is incredibly encouraging.
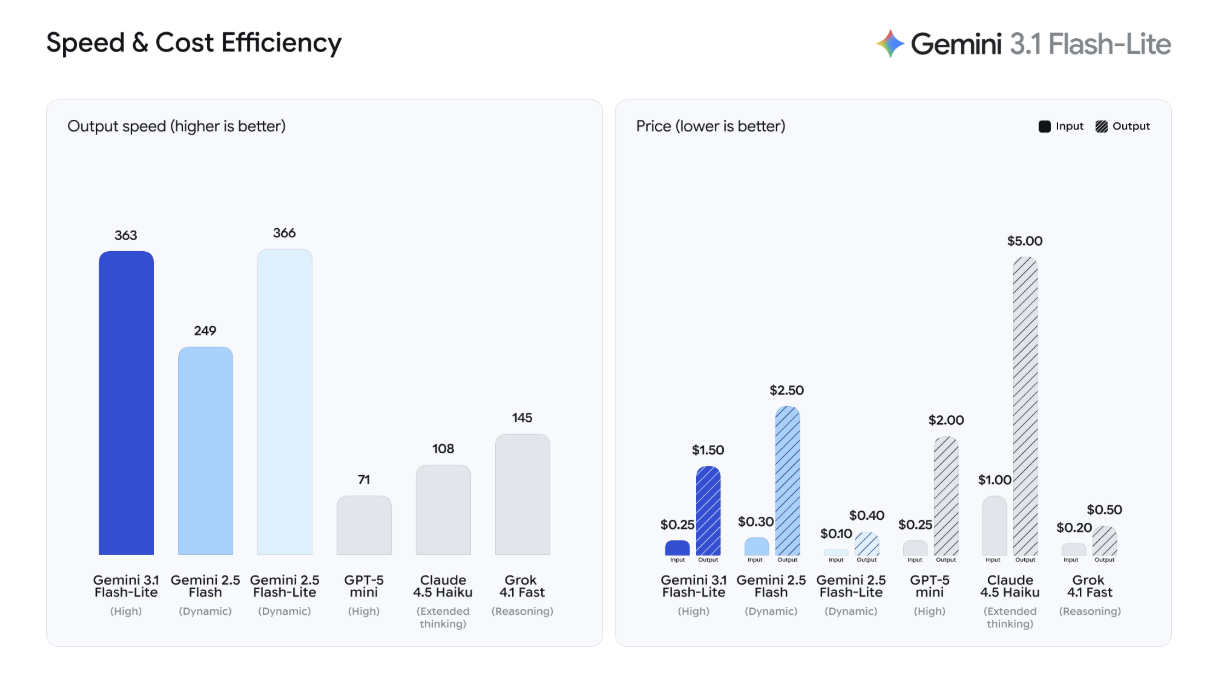
Comparison with Rival AI Models
Affordability hasn't come at the expense of performance, however. As shown in the Leaderboard (2), it boasts a score exceeding 1430. Given that the top-tier frontier models are currently competing around the 1500 mark, a score of 1430 for a lightweight model is truly outstanding.
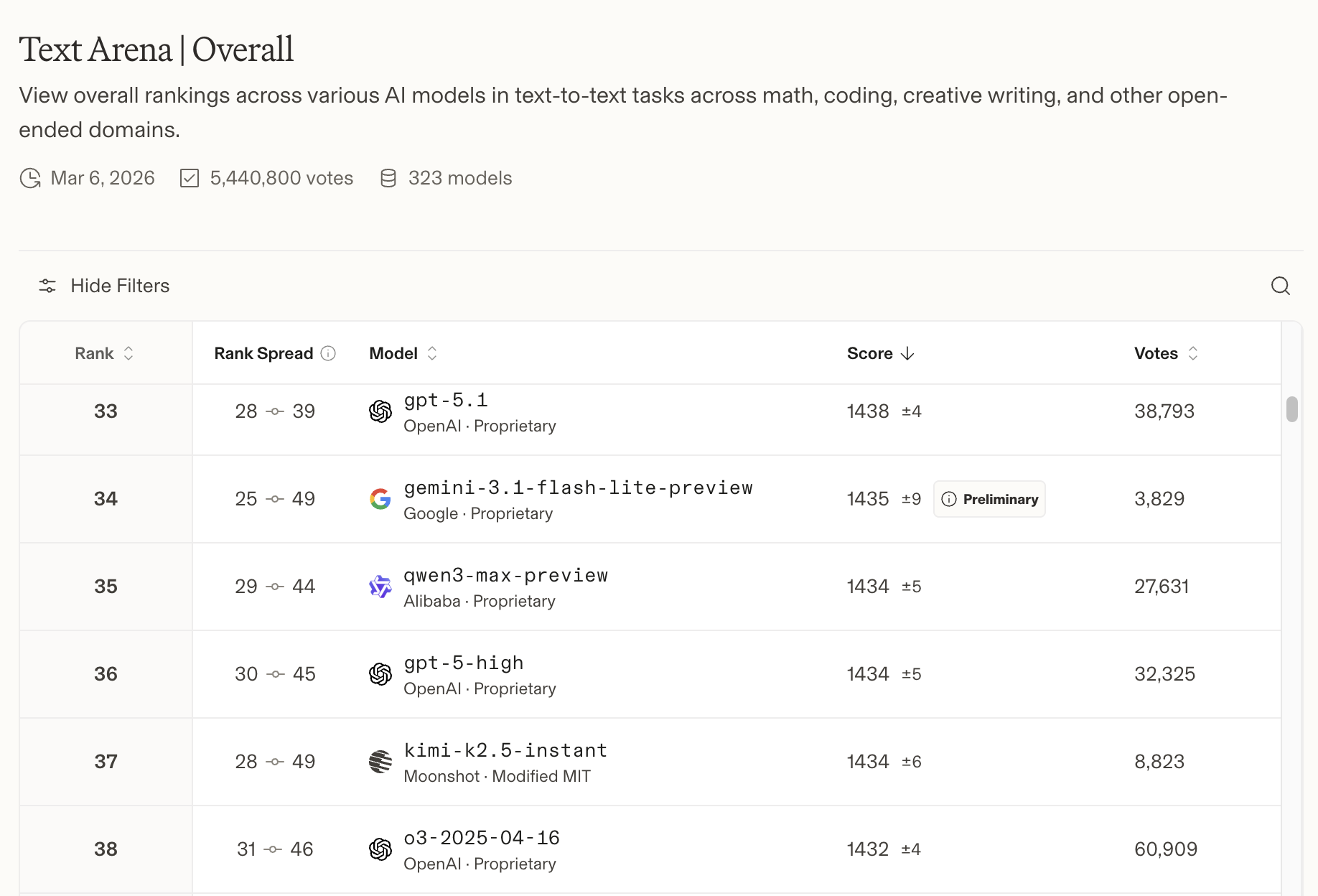
Leaderboard Standings
2. Performance Evaluation: Banking Complaint Classification
To see what it can really do, I tested the model on a banking complaint classification task. Using this dataset (3), I provided the model with customer complaints from the "text" column and asked it to select the most relevant category from six financial products listed in the "Product" column. I ran this test on 100 samples to see how accurately it could categorize each complaint.
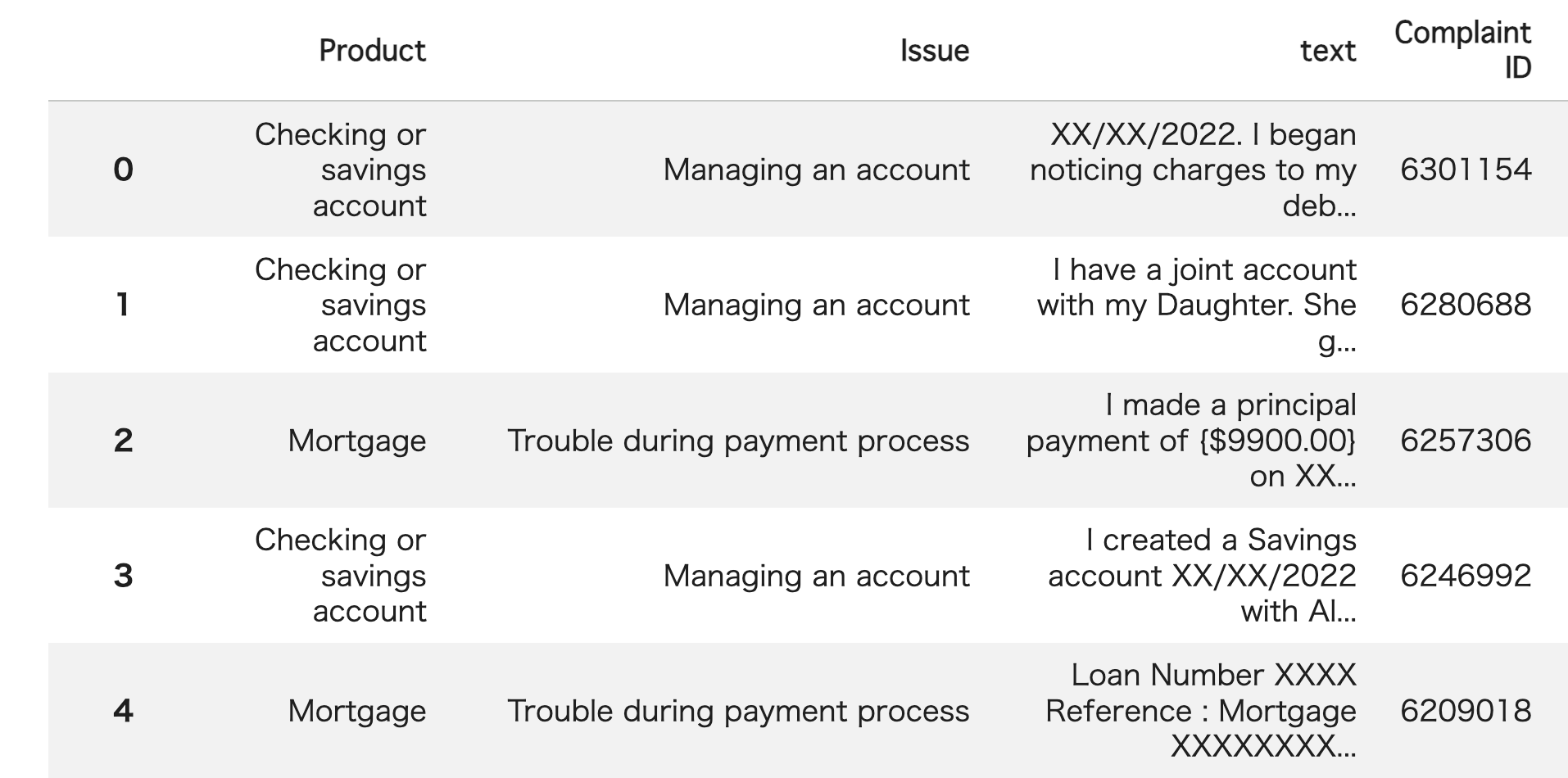
Banking Complaint Data
Here is the detailed prompt I used.

The Prompt
The results were fantastic, achieving a 92% accuracy rate. The entire process finished in about 60 seconds, demonstrating its high-speed processing capabilities. I’ve attempted this specific task several times in the past, but this is the first time a model has exceeded 90% accuracy without any fine-tuning. Truly impressive!

Task Accuracy Results
3. A High-Speed Model You Can Use Without Budget Anxiety
For the past few months, I’ve relied on Opus 4.6 for its sheer coding power. While its performance is top-notch, the costs are substantial. When you want to run various experiments where success isn't guaranteed, the budget can become a significant hurdle.
That’s where gemini-3.1-flash-lite-preview shines. Its balance of performance and cost makes it easy to iterate and experiment freely. It’s the perfect "partner" for development, and I plan to integrate it into my workflow even more moving forward.
What do you think? It looks like Google will continue to roll out new AI models one after another. We might even see some open-source models soon, so it's definitely something to keep an eye on. Here at ToshiStats, we’ll keep testing and integrating various AI models into our workflow. Stay tuned!
You can enjoy our video news ToshiStats-AI from this link, too!
1) Gemini 3.1 Flash-Lite: Built for intelligence at scale, Google, Mar 03, 2026
2) Arena
3) Consumer Complaint Database
Copyright © 2026 ToshiStats Co., Ltd. All right reserved.
Notice: This is for educational purpose only. ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the report, the codes and the software.