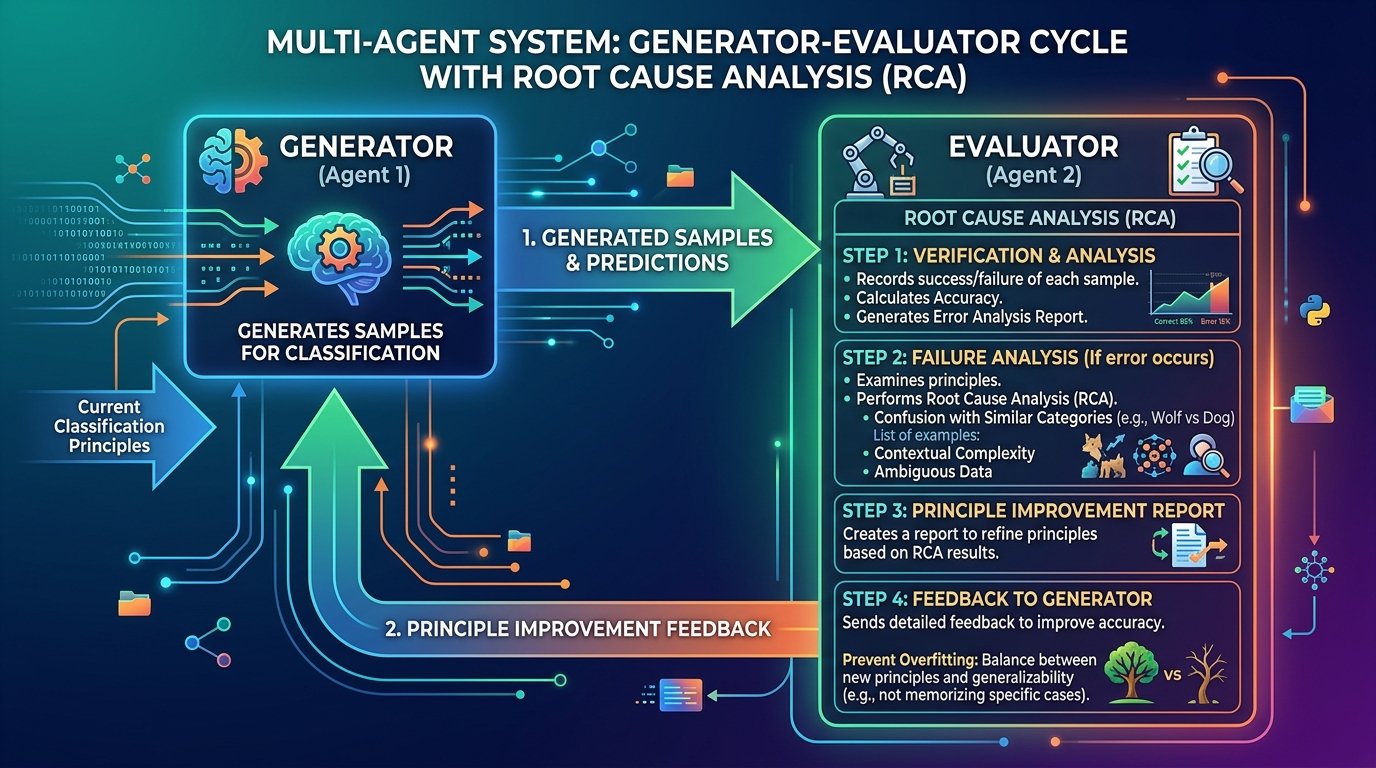
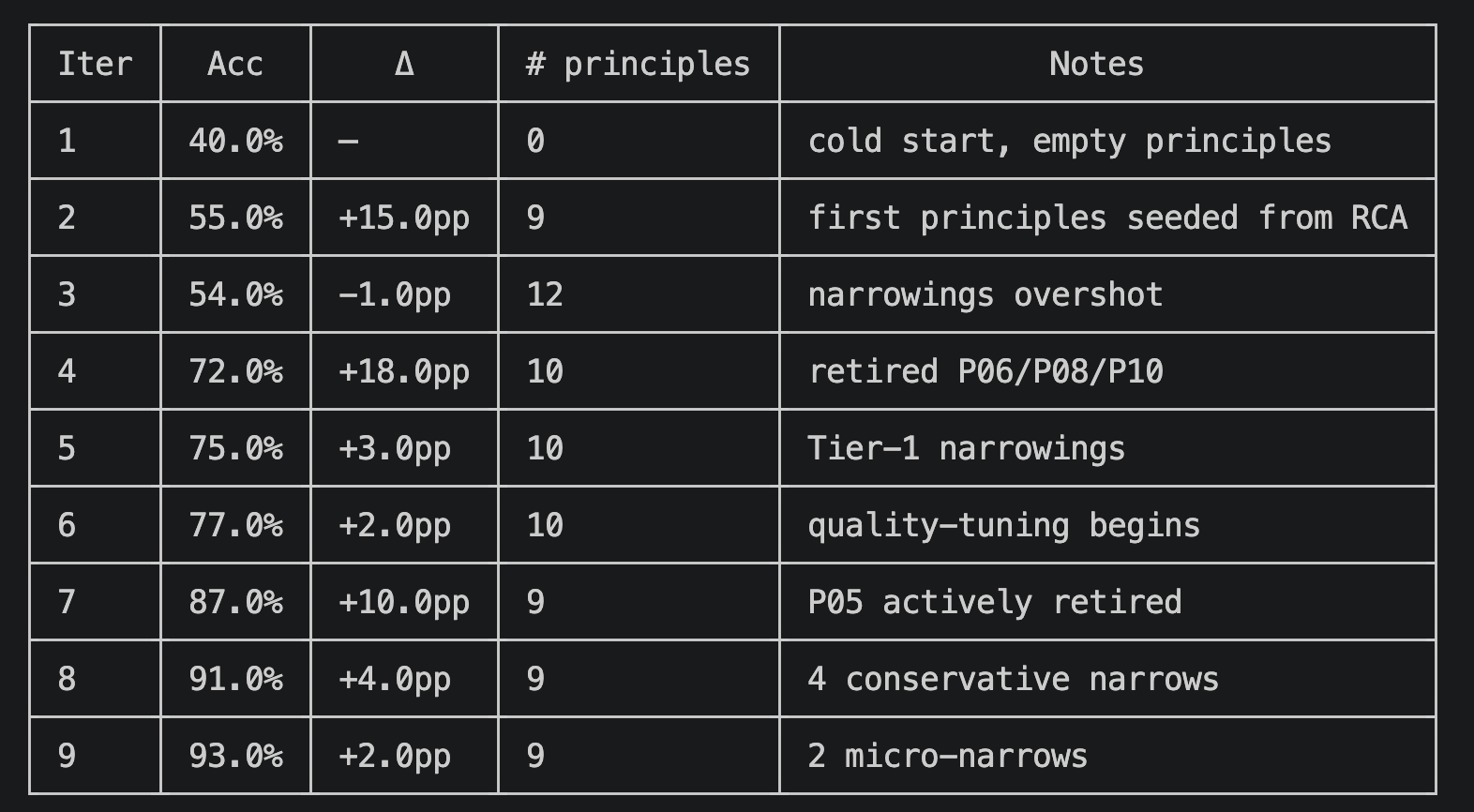
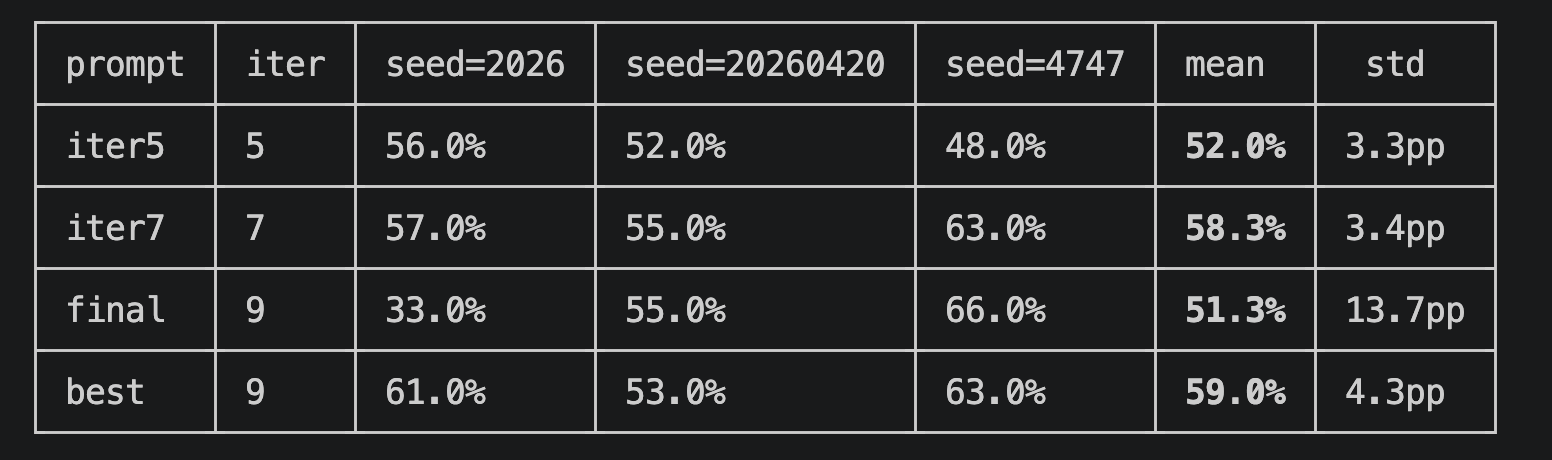
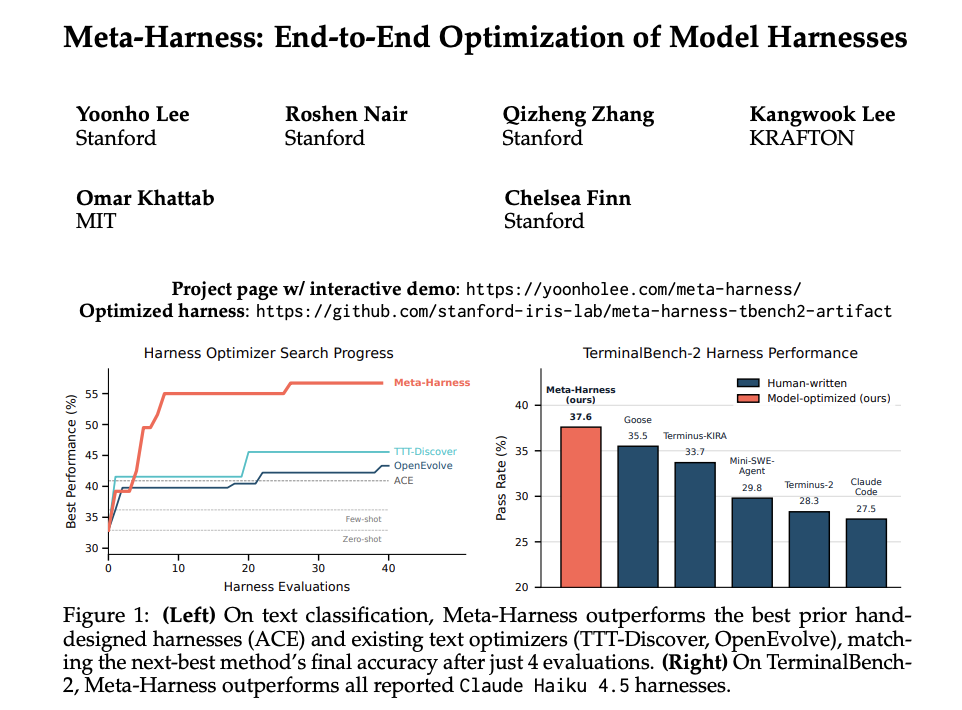
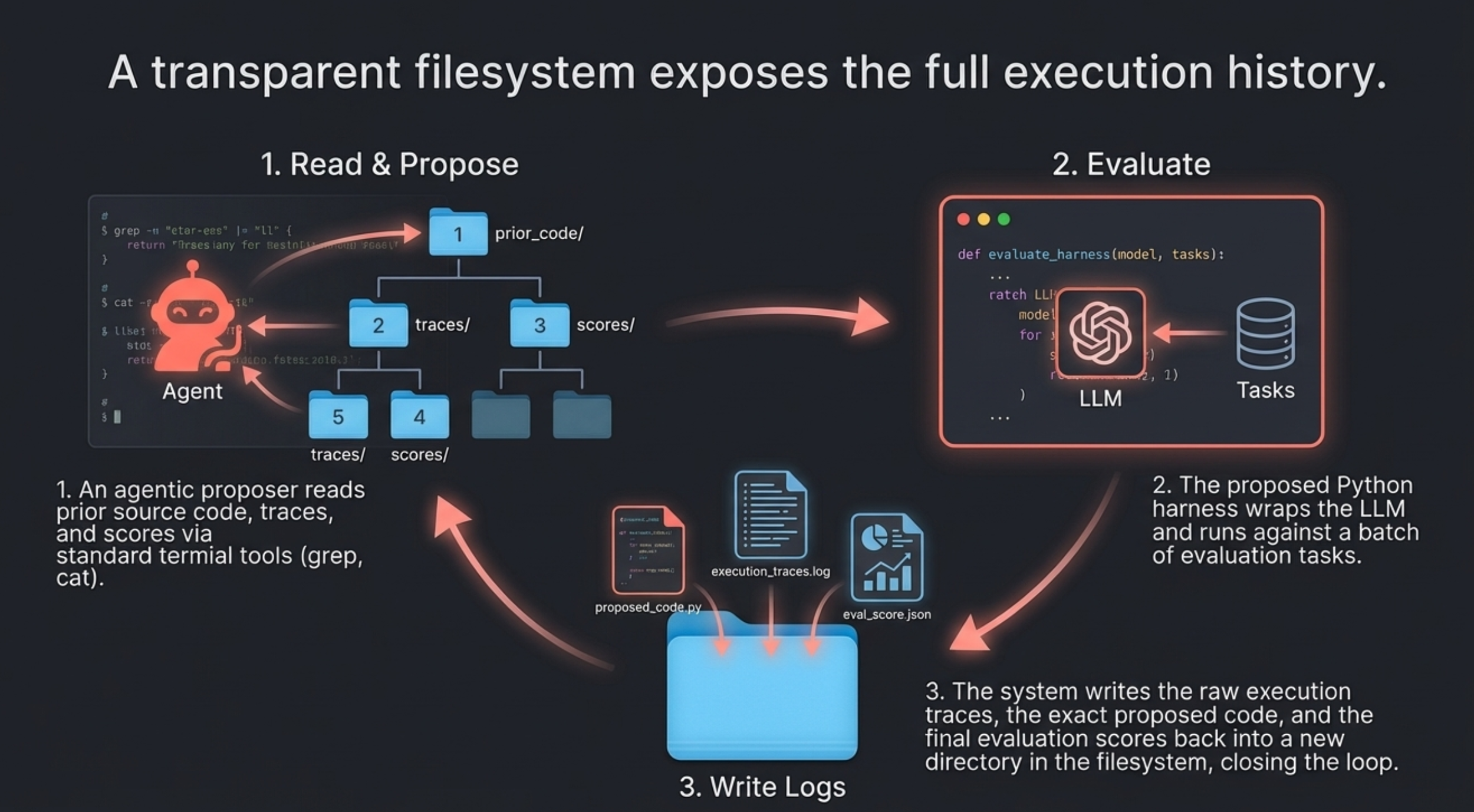
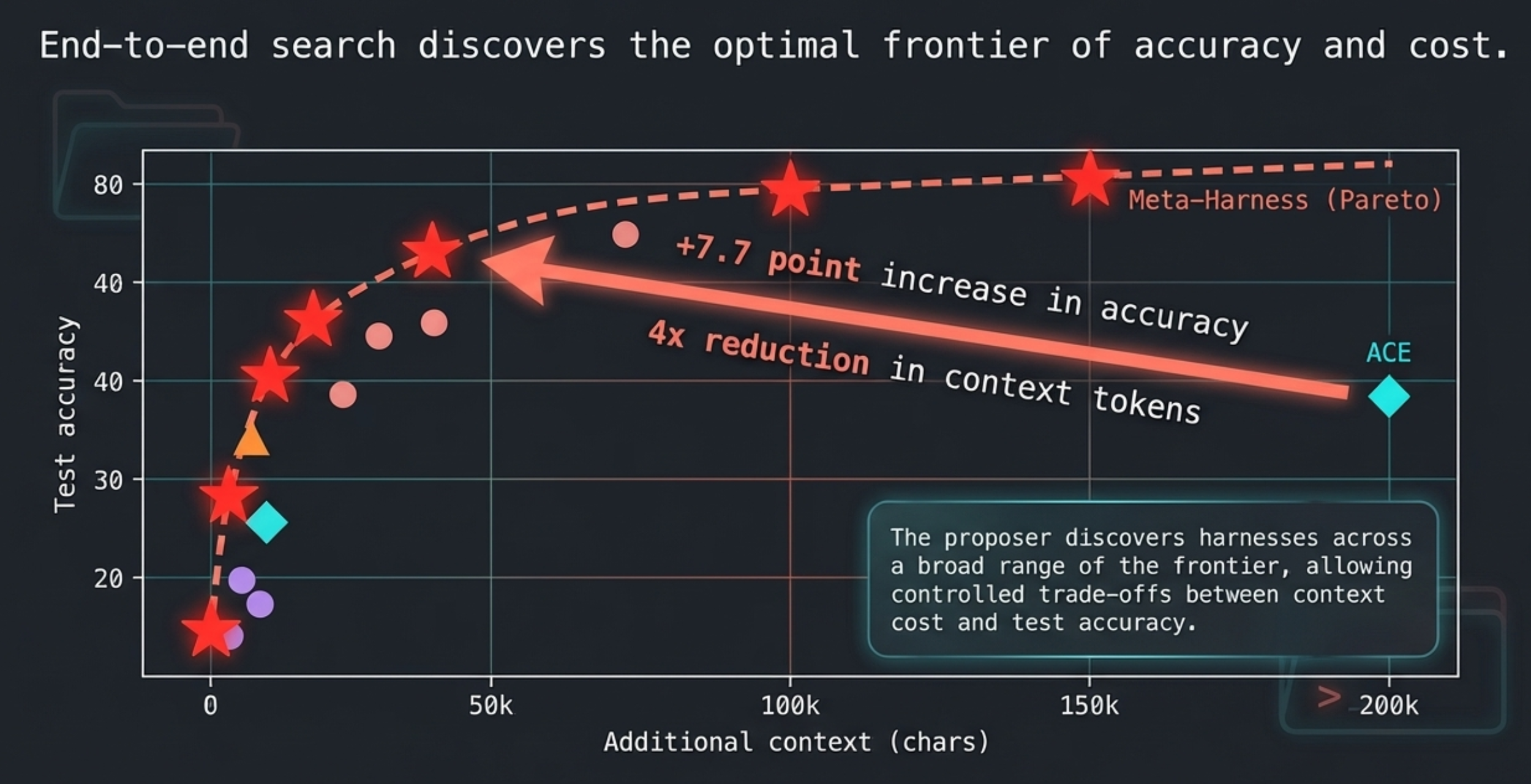
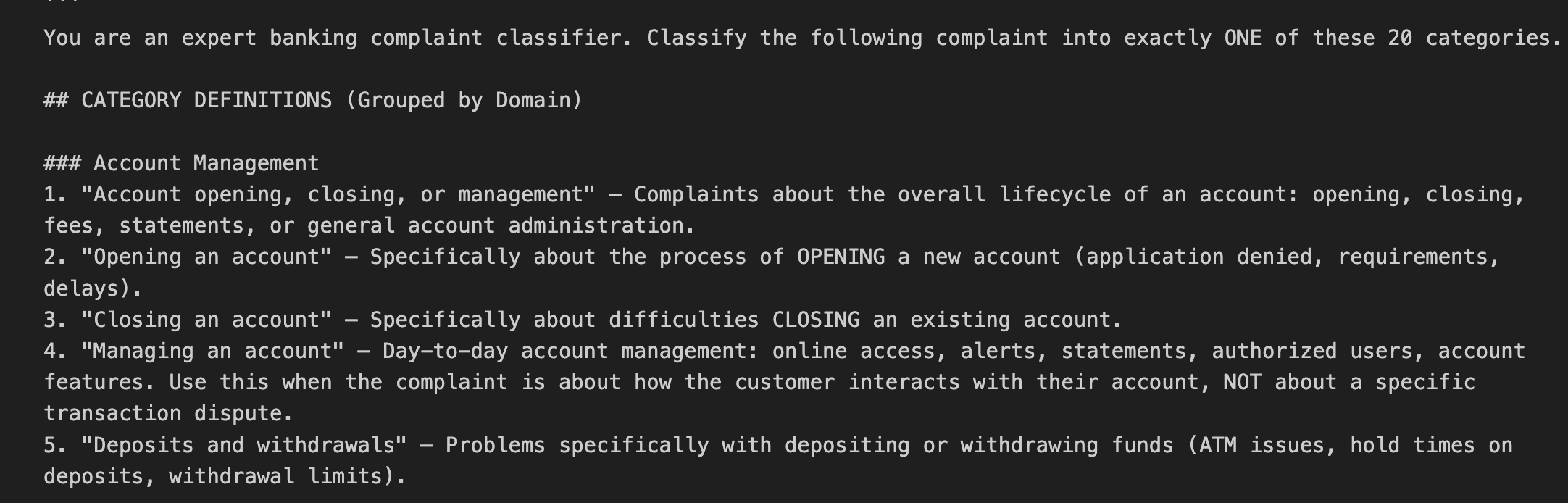
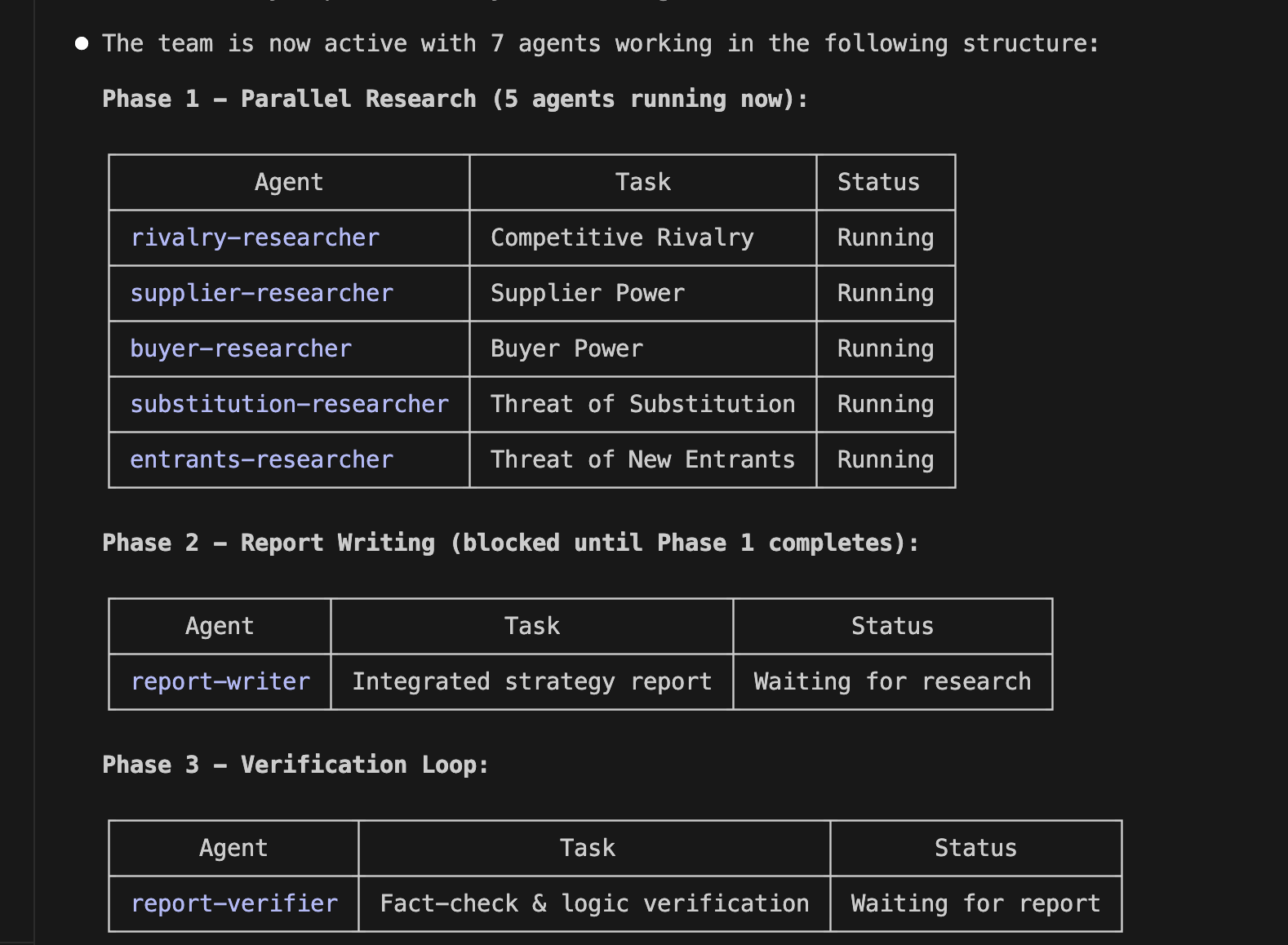
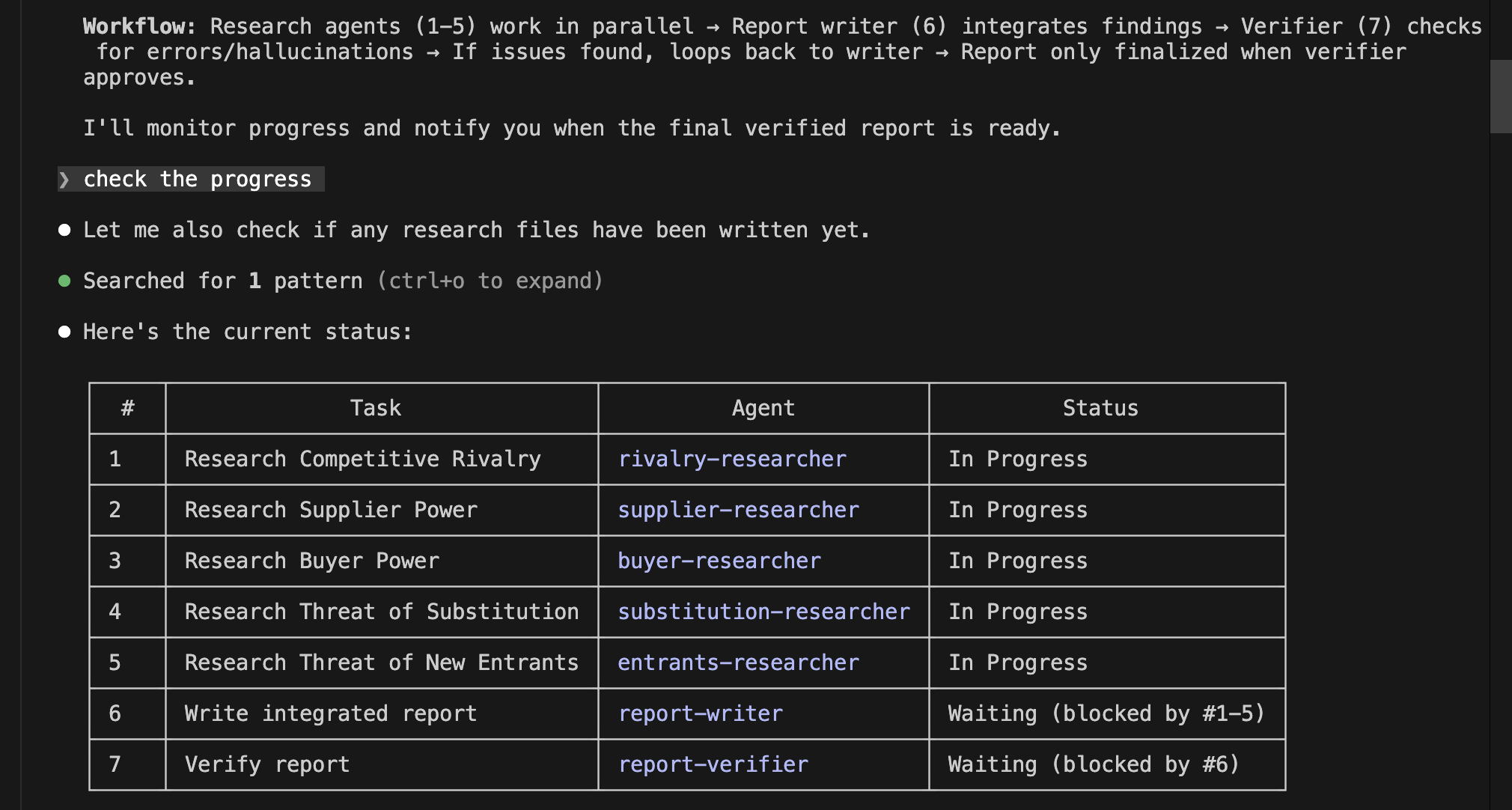
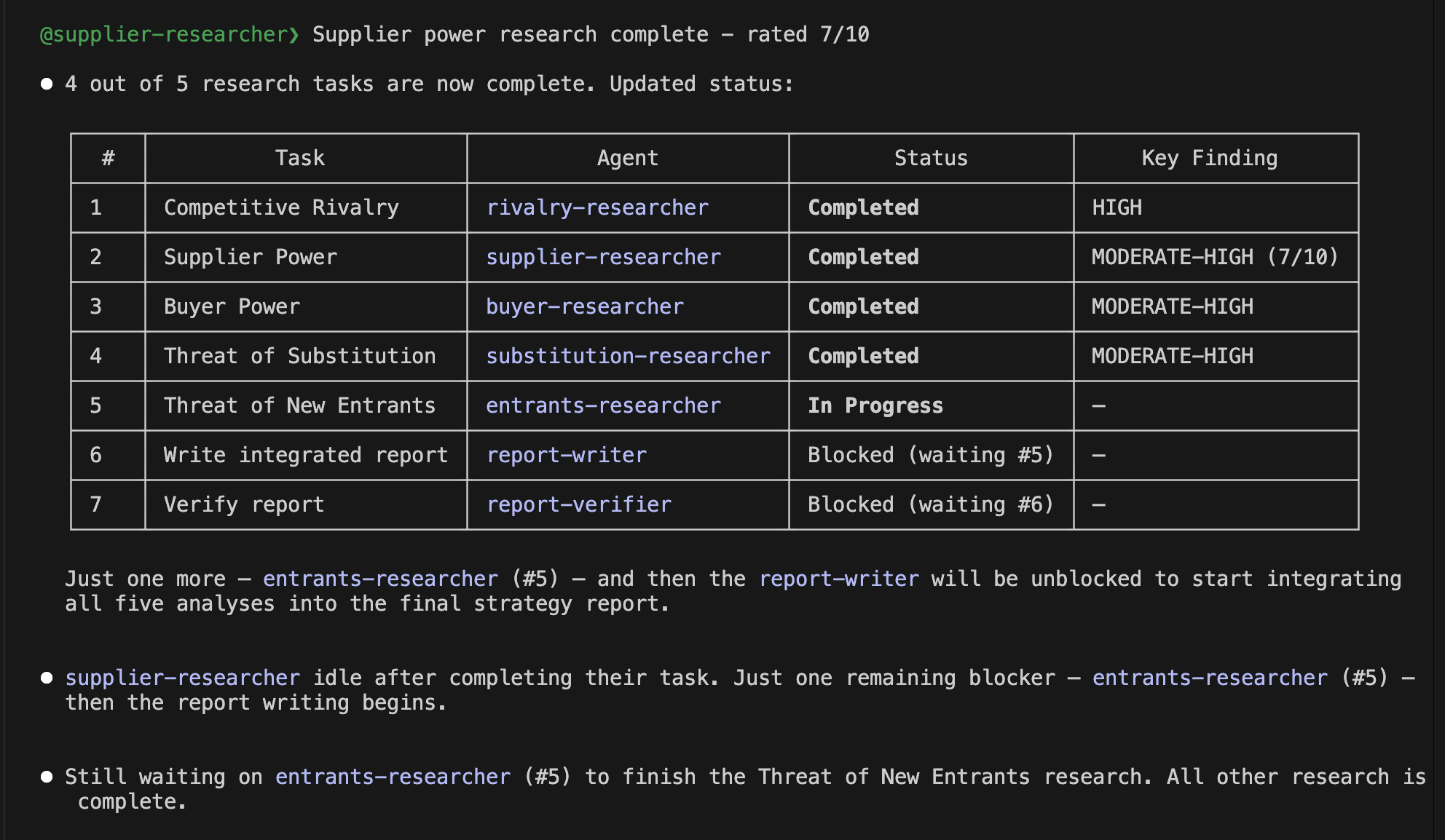
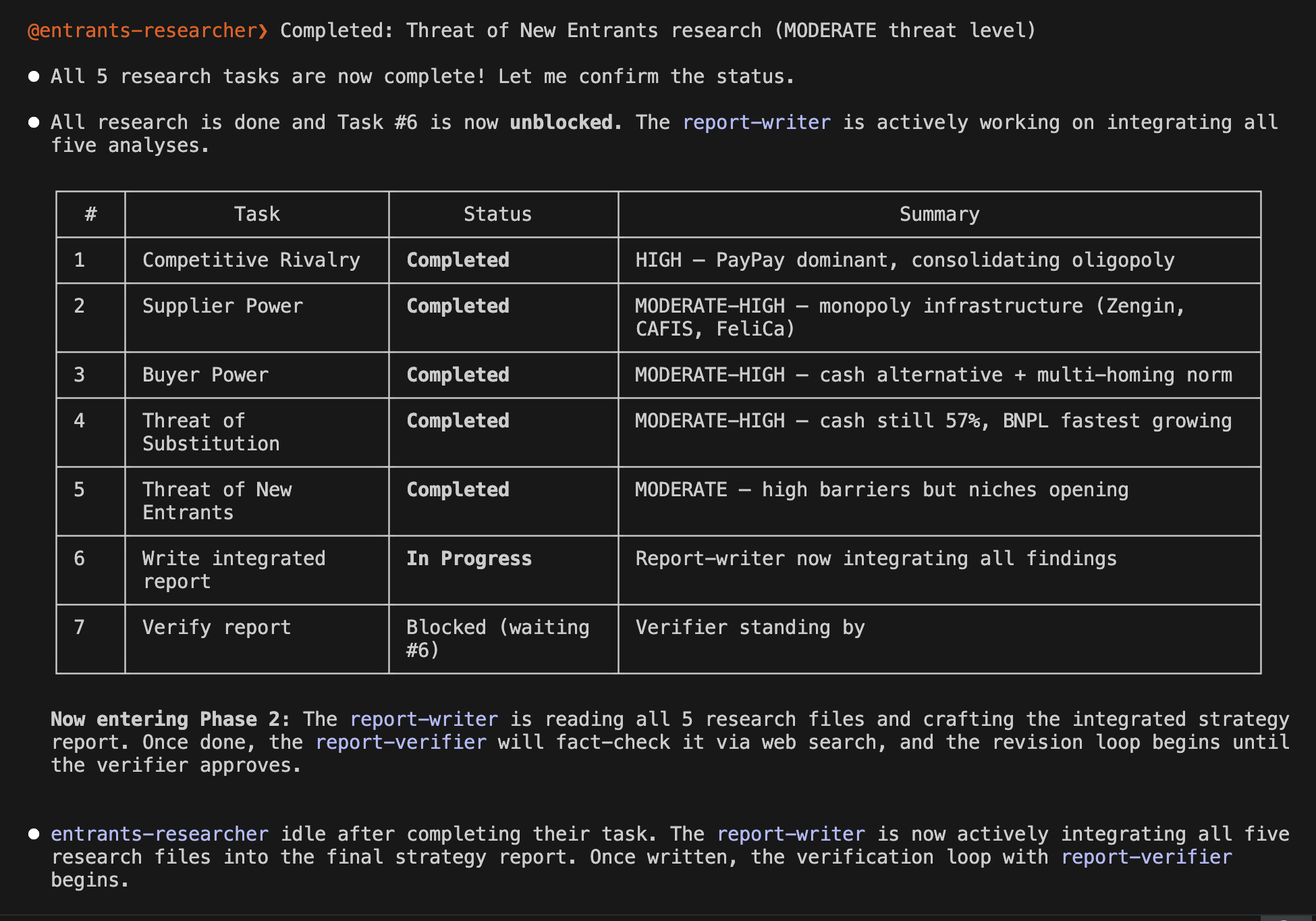
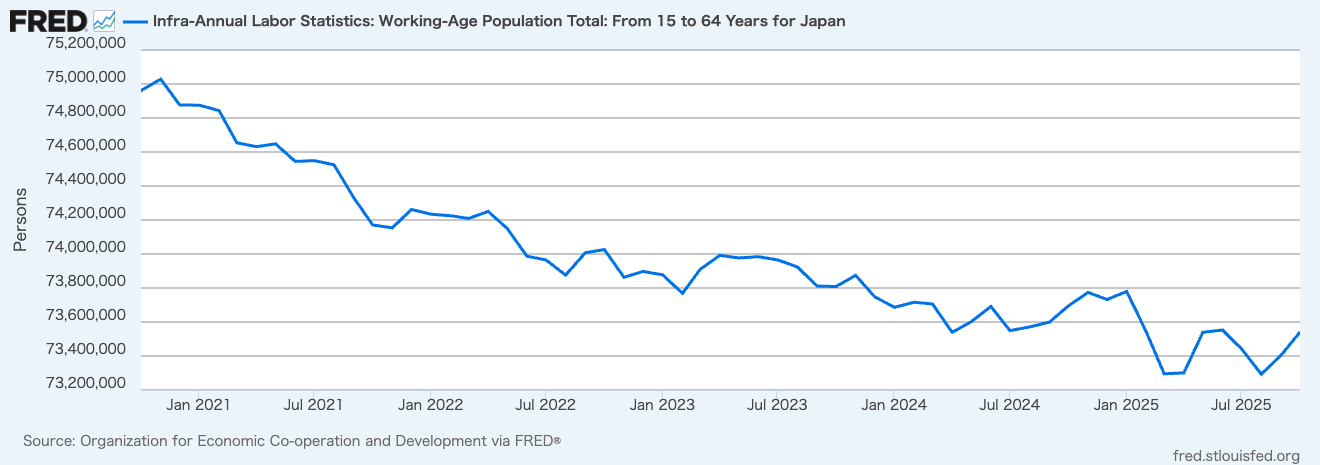
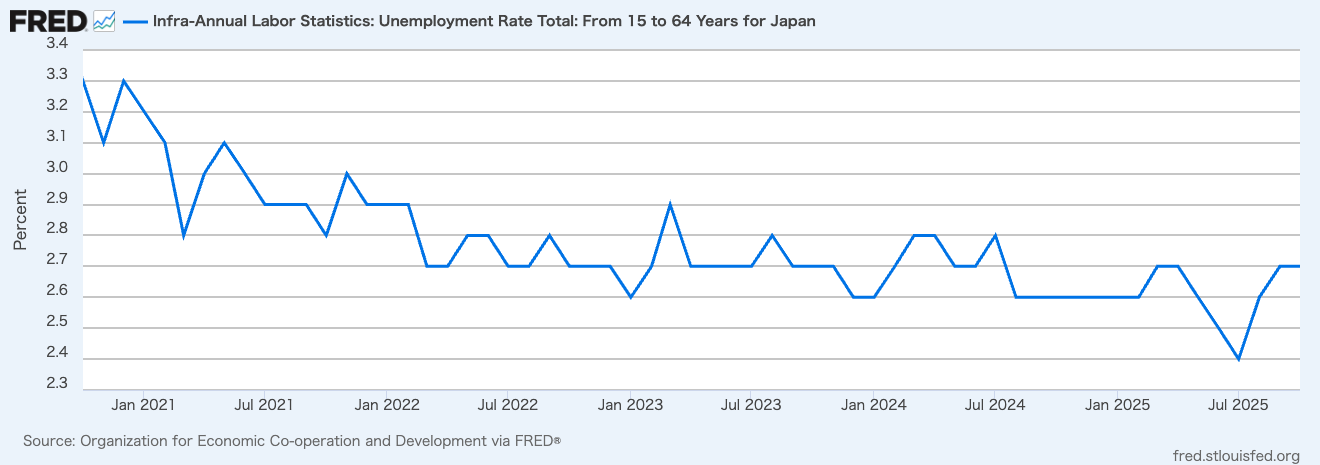
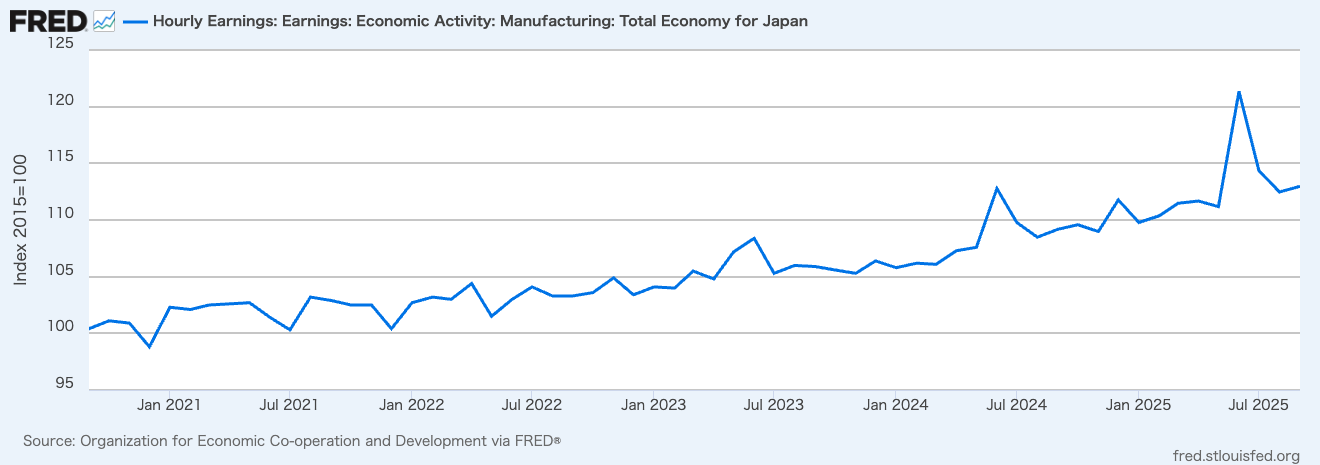
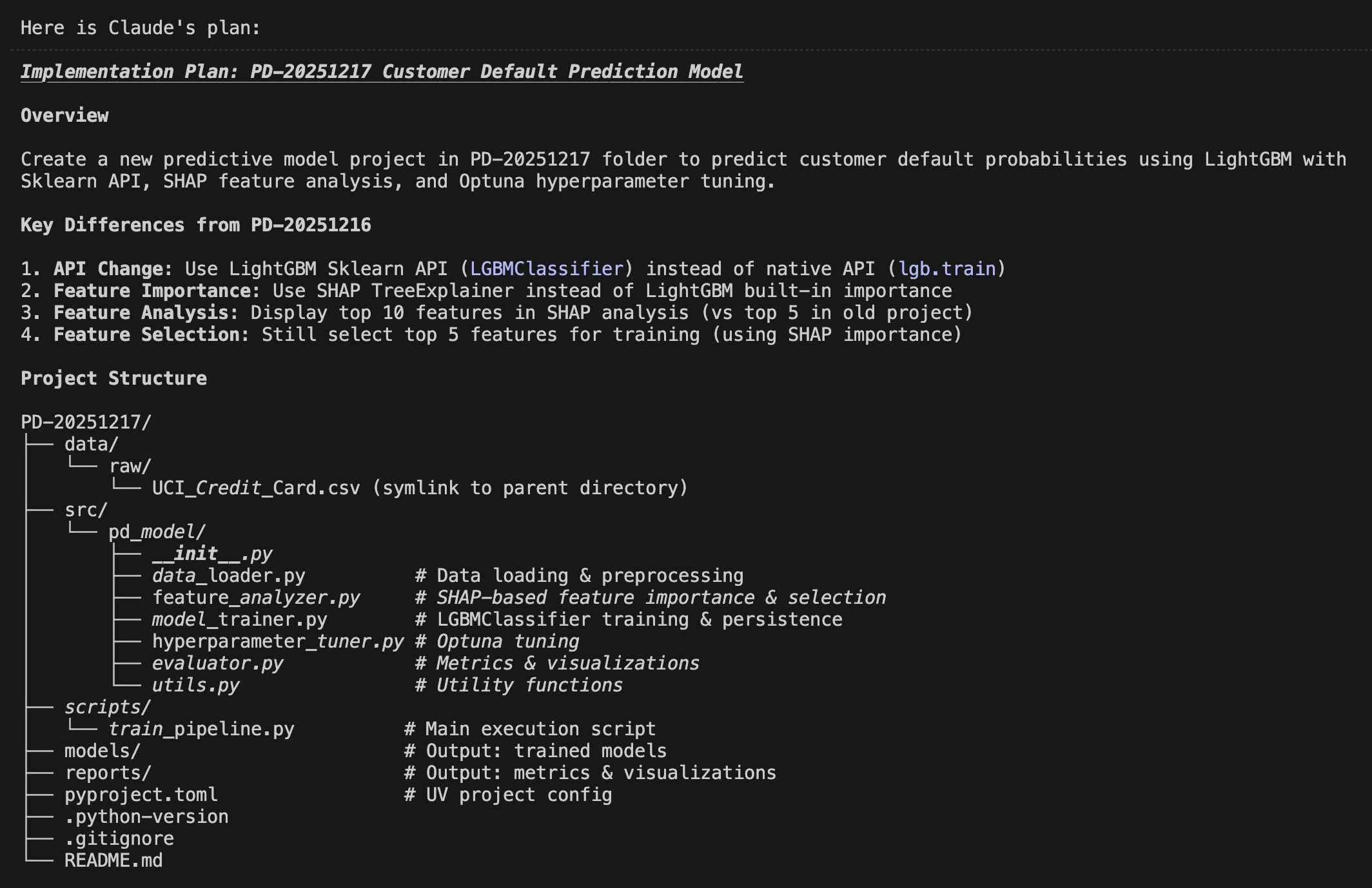
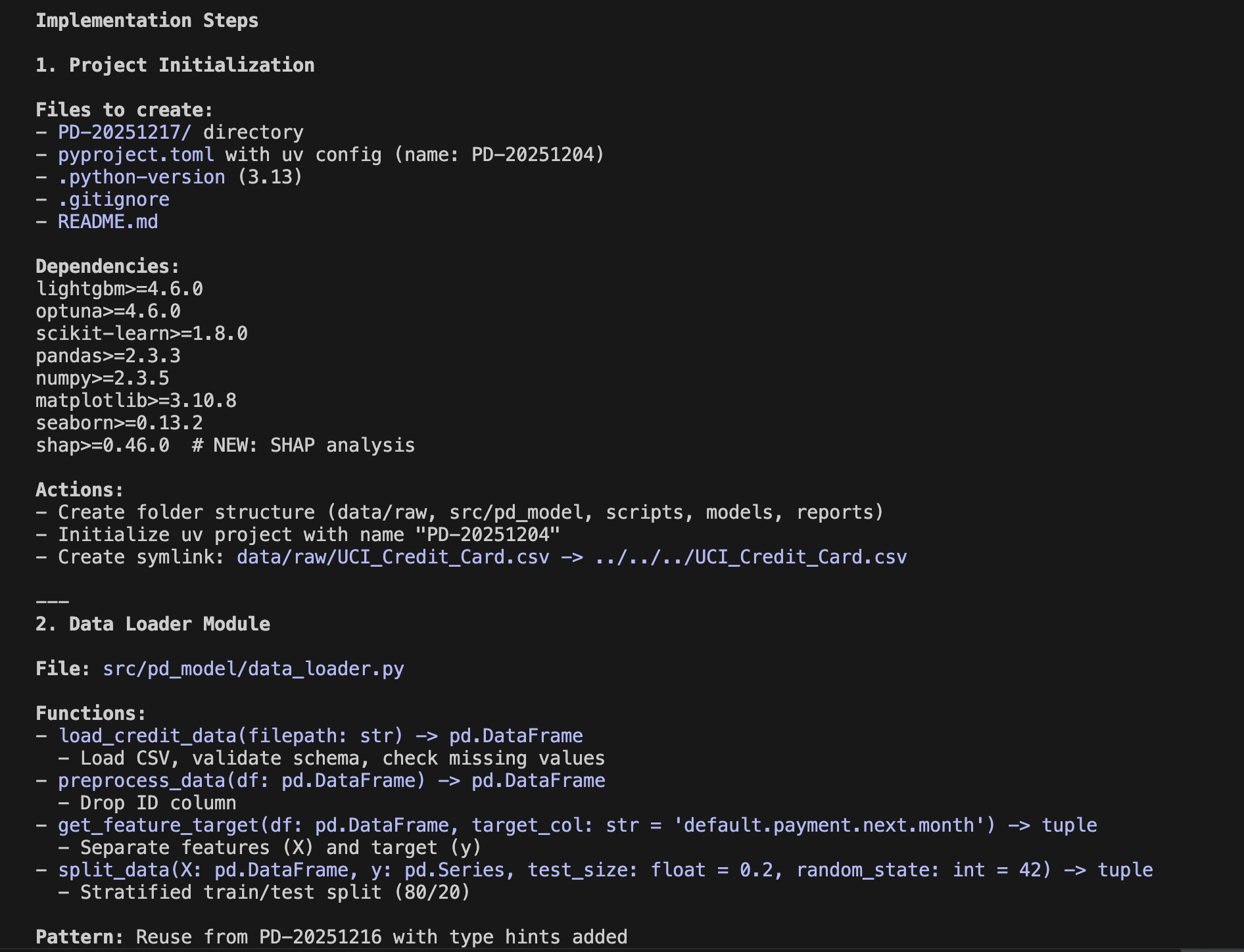
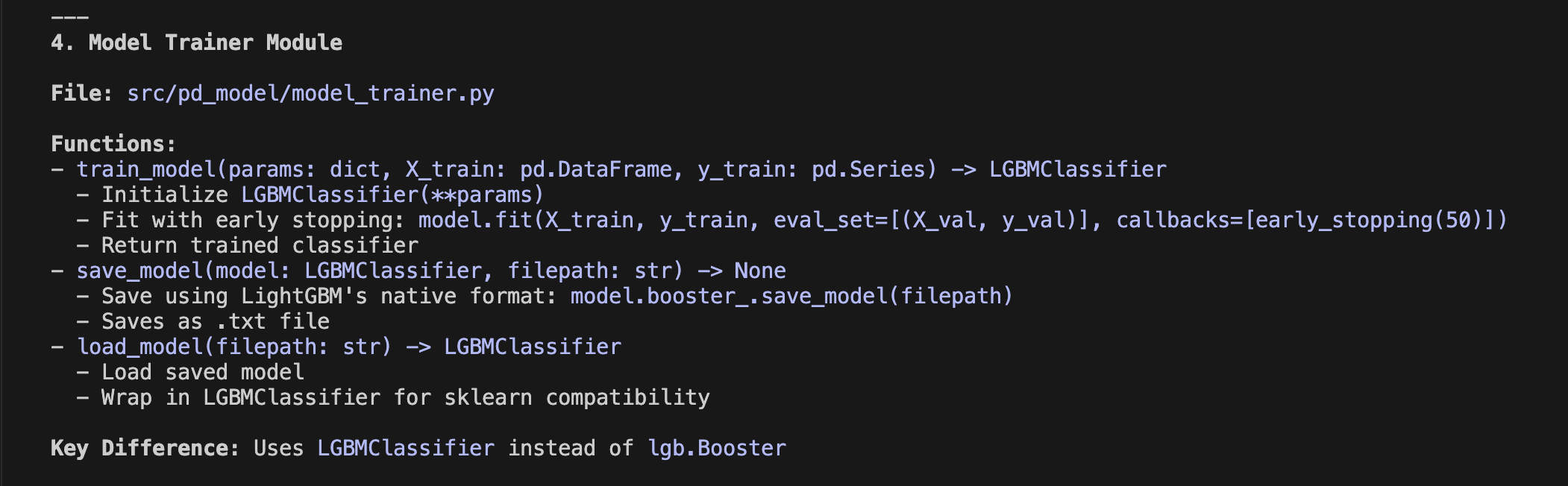
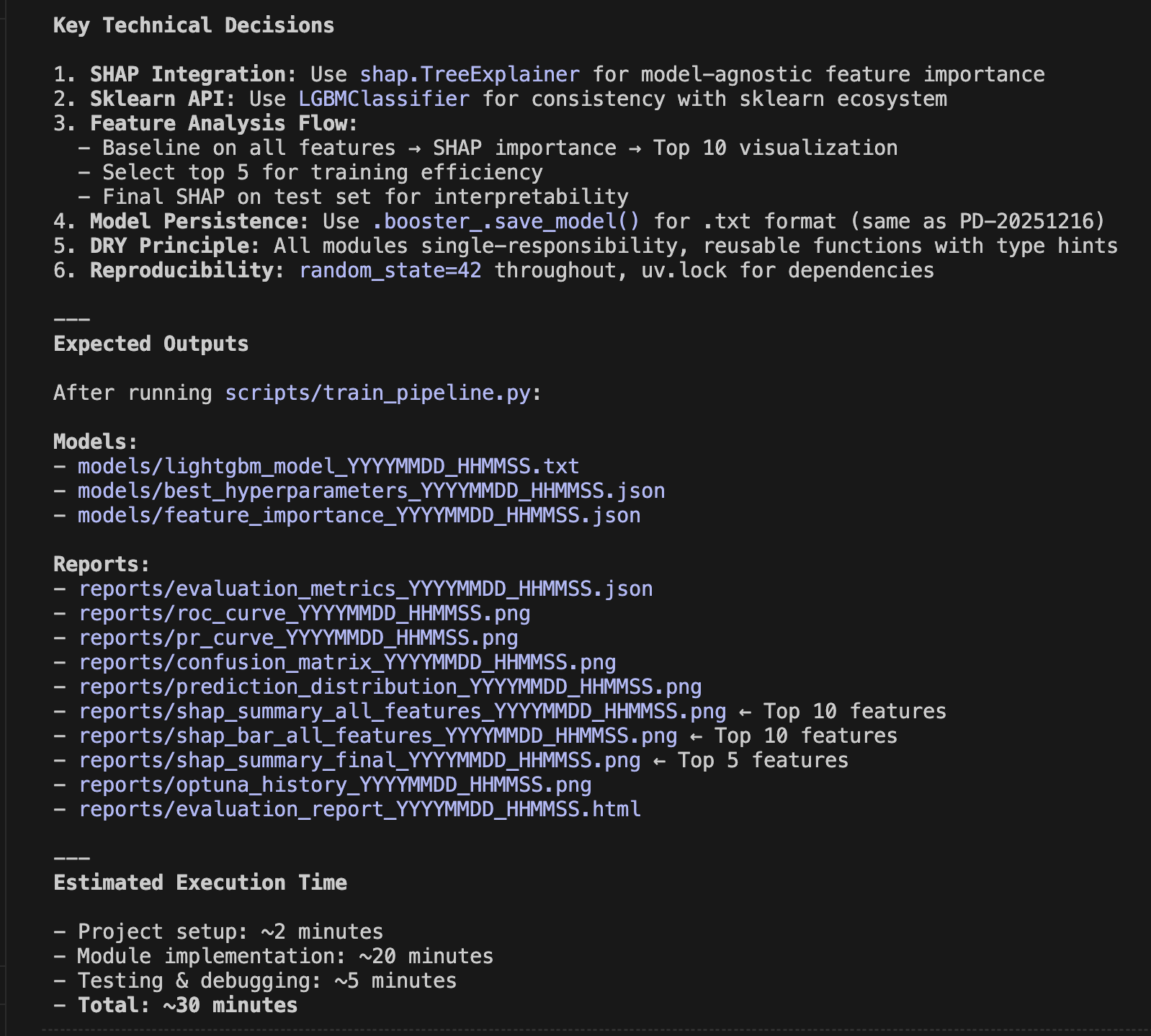
Have you ever worried about the next billing amount when running a generative AI for long hours? This is especially true since high-performance frontier models can easily run continuously for half a day or more. While we understand the incredible performance they offer, I'm sure many of you are wondering, "Isn't there a way to operate generative AI at a lower cost?" So, today, I would like to introduce "Gemma 4 E2B", an open-weight generative AI that you can download and use right on your local PC.
1. The Highly Anticipated Open-Weight Generative AI from Google: "Gemma 4 E2B"
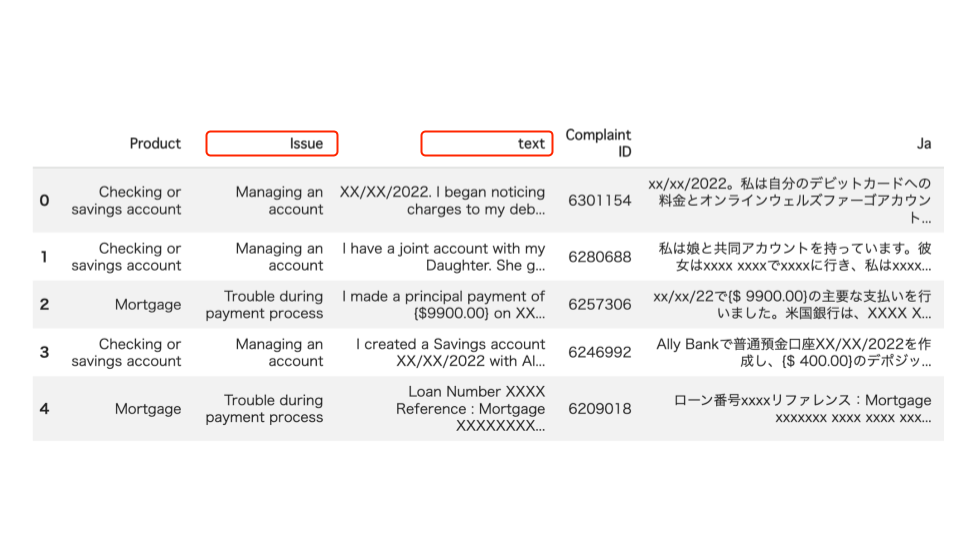
Various AI companies have released open-weight generative AI models. My personal focus is on the Gemma series from Google, which is now in its 4th generation. It has steadily powered up with each generation, and among them, the performance of the smallest latest version, "Gemma 4 E2B QAT" (1), is particularly outstanding. This time, I built an application that predicts customer churn by combining machine learning with "Gemma 4 E2B QAT."
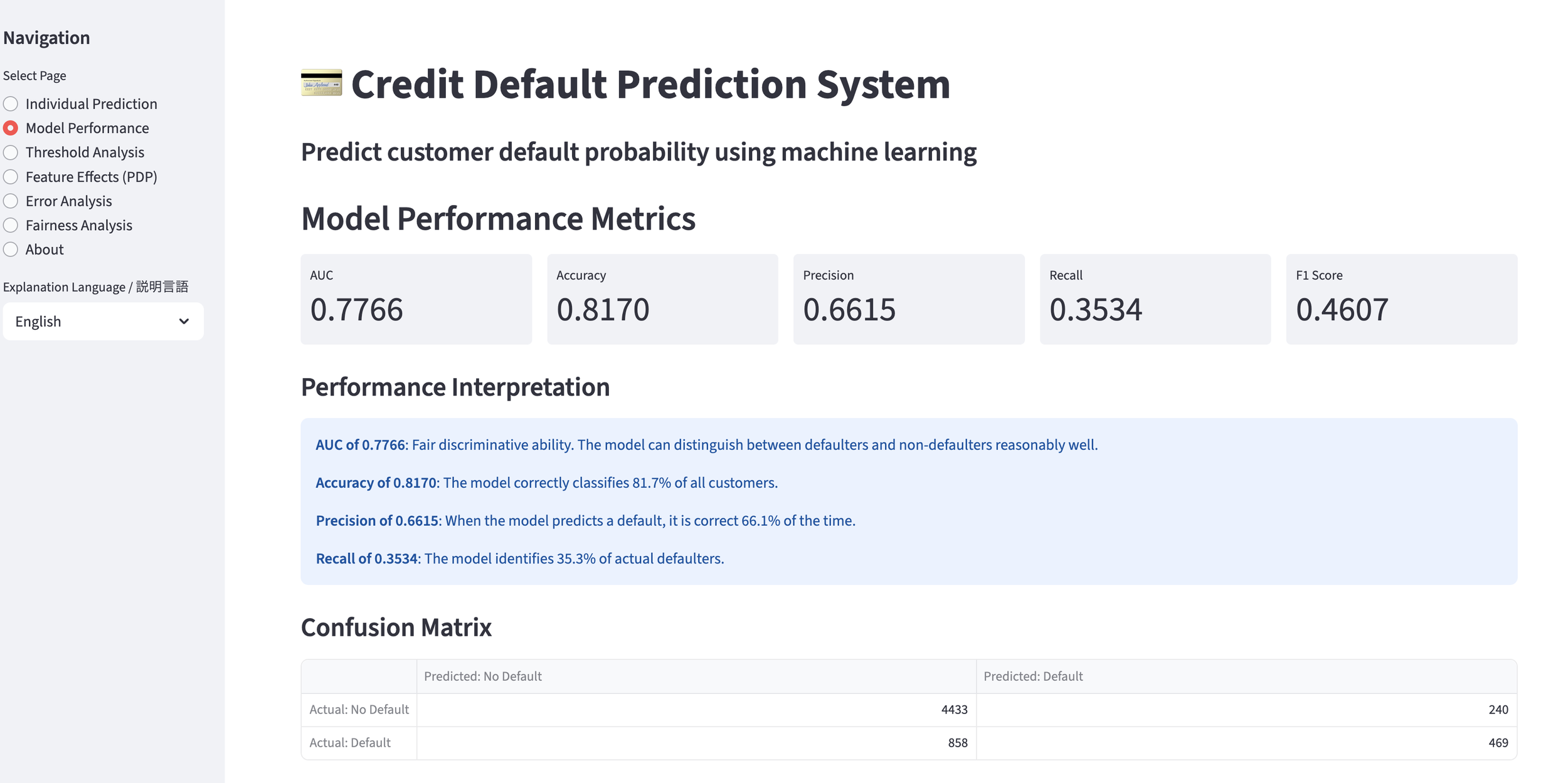
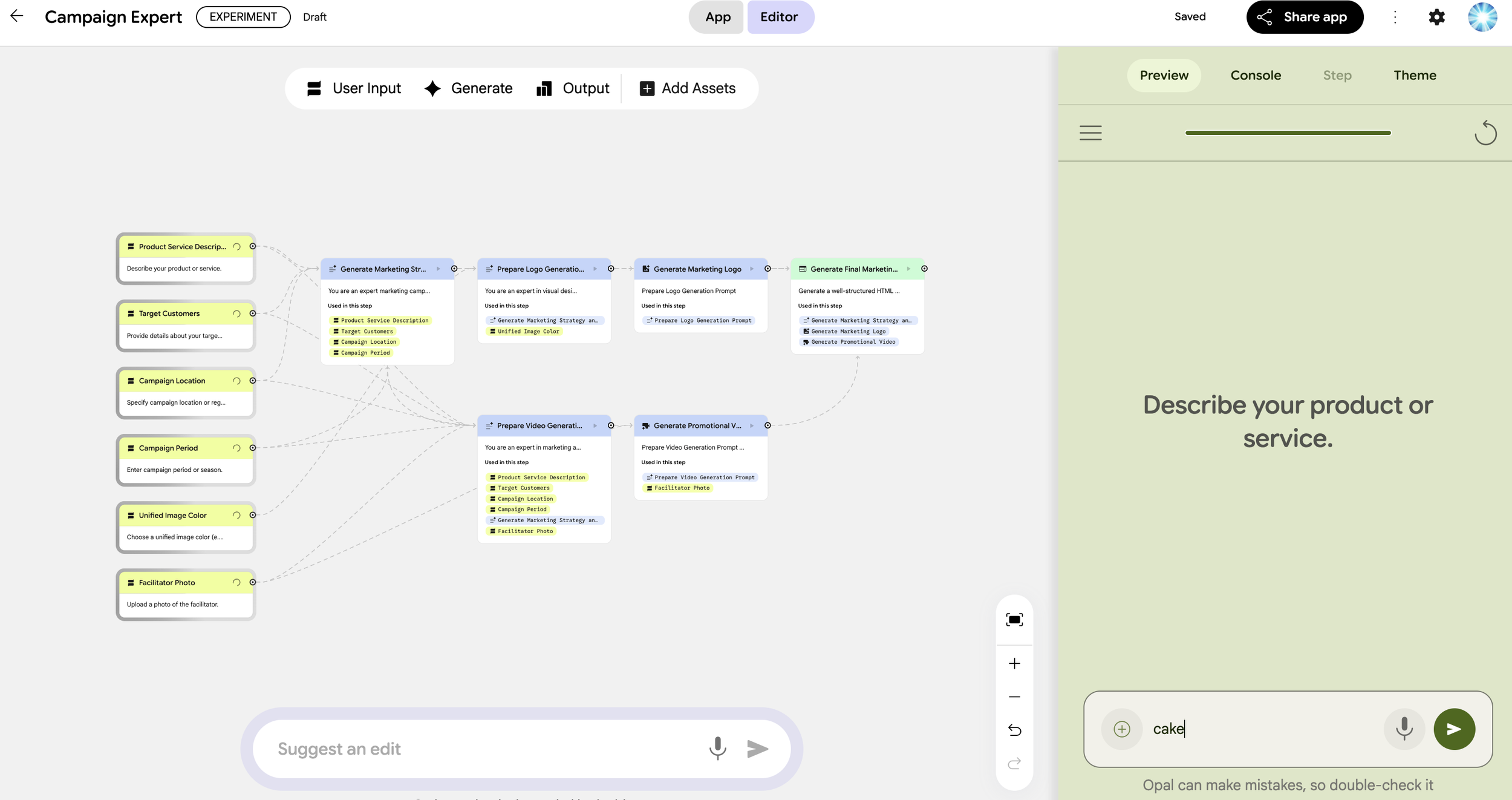
Here is its GUI. For this version, it features bilingual specifications supporting both English and Malay. This is the screen for training the machine learning model.

Model Training Screen (English)]
You can switch it to Malay as shown below. It makes it easy to use even in Kuala Lumpur, the capital of Malaysia!

Model Training Screen (Malay)
2. Exploring the Probability of Individual Customer Churn
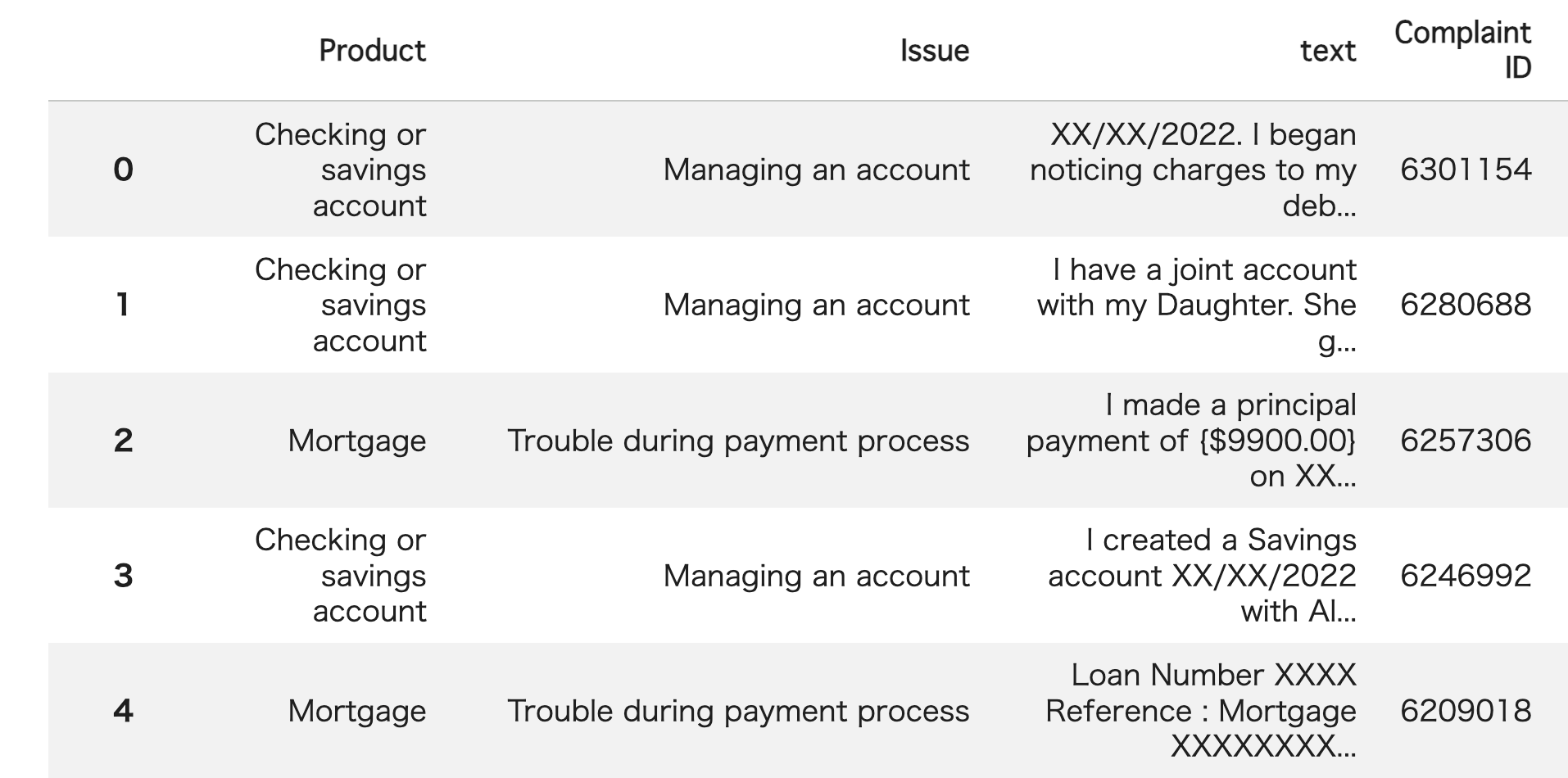
Now, let's get down to business. By inputting individual customer data into the machine learning model, you can calculate the probability of that customer churning. Here, the system is set so that if the probability is 50% or higher, the customer is predicted to churn. The churn probability for the customer shown on this screen is 15.01%, so they were judged as "will not churn."

Customer Data
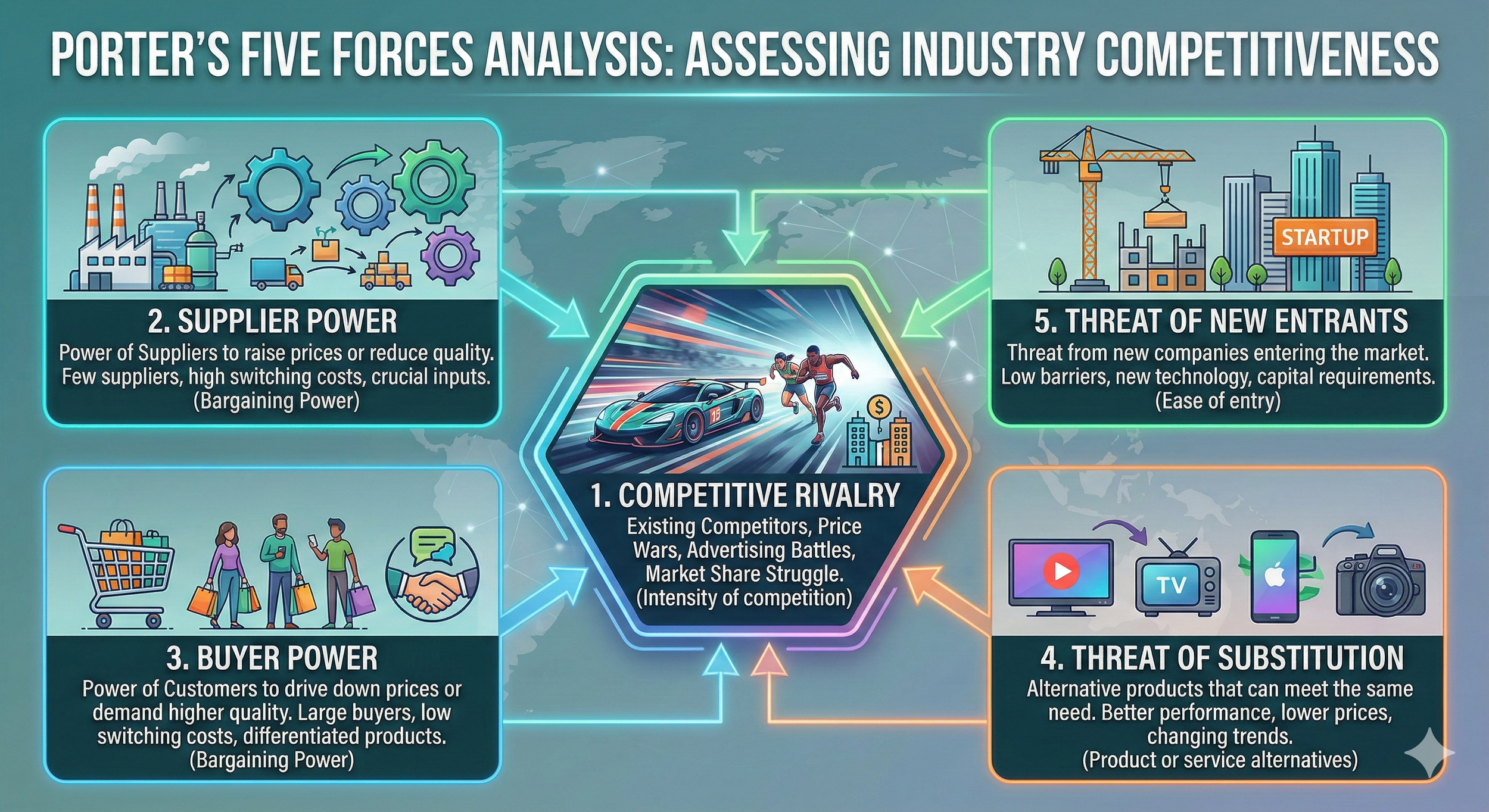
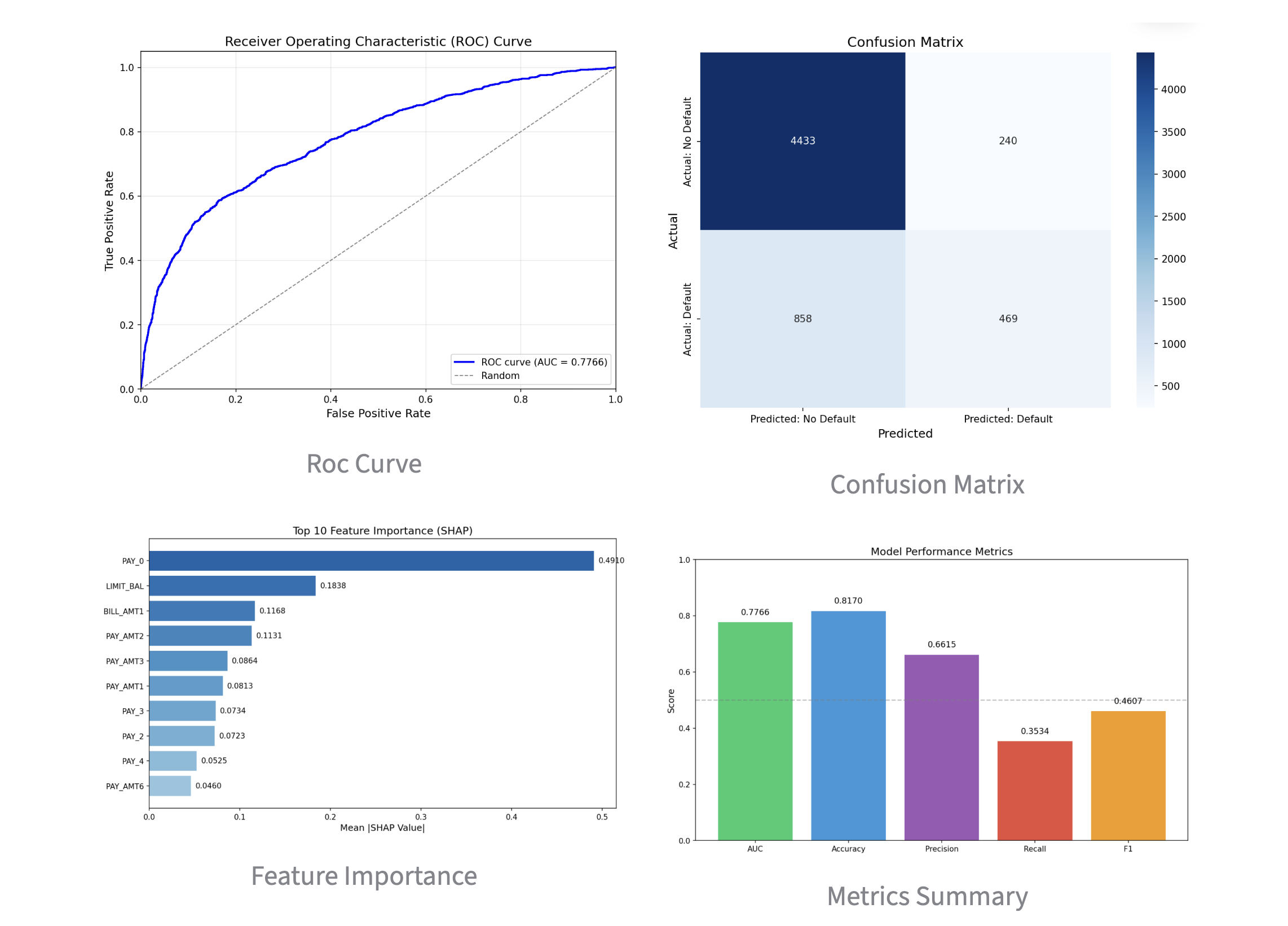
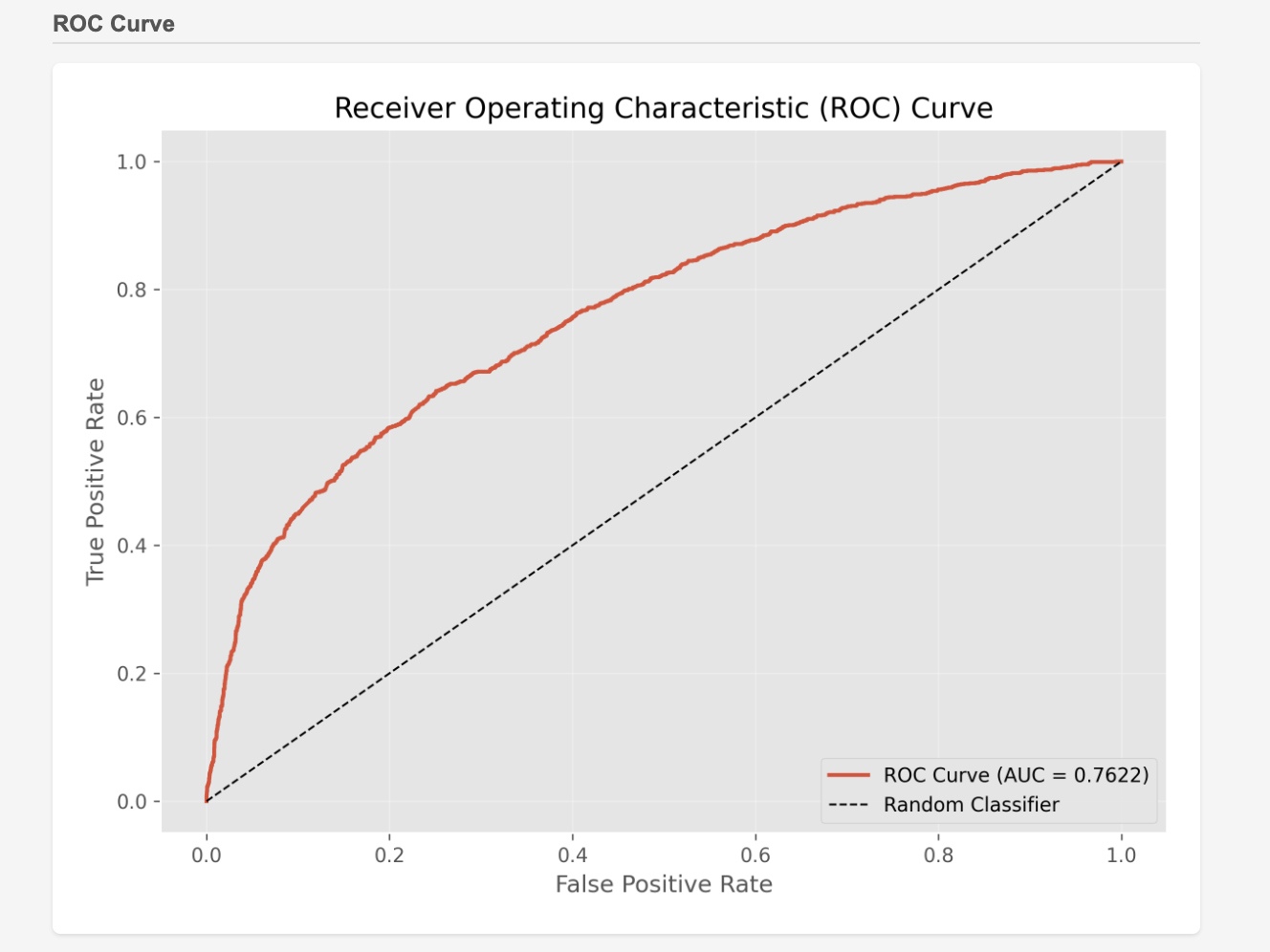
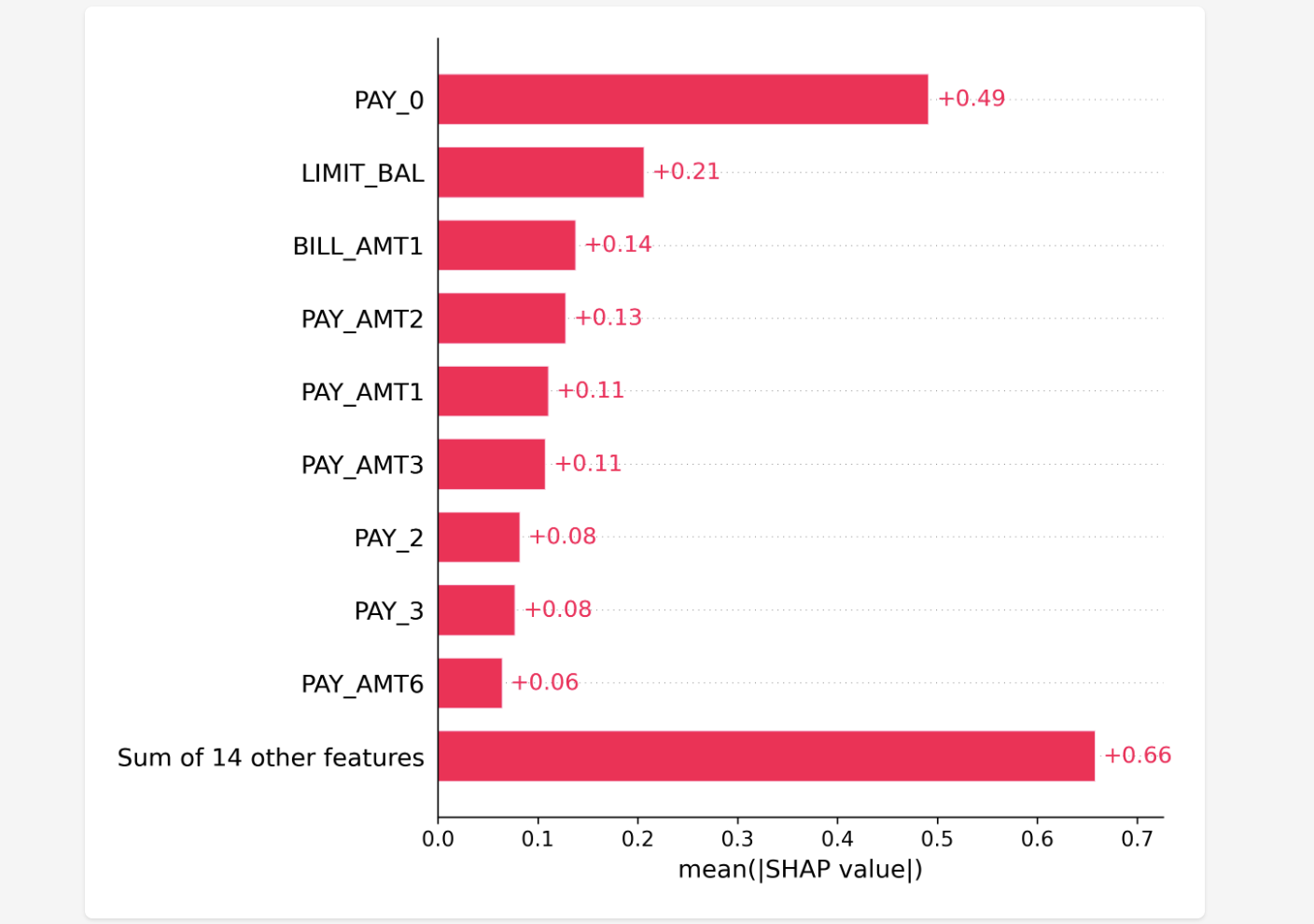
What's really important here is the reasoning behind why it decided they wouldn't churn. For this, a metric called SHAP (2) is employed. The graph below shows numerically and visually how much each feature contributed to the decision.

Churn Probability and SHAP
However, the problem here is that SHAP is mostly well-known only to data scientists, and there's a high chance that ordinary business professionals aren't familiar with it at all. Therefore, simply saying "Please look at this graph" isn't very user-friendly.
This is where today's star, "Gemma 4 E2B QAT," steps in. As shown below, it explains the "basis for the decision" and the "model's accuracy" in plain, easy-to-understand English. With this, even a SHAP beginner can use it with absolute confidence.

Explanation of Decision Basis and Model Accuracy (English)
Of course, you can switch this to Malay. Generating this much explanatory text in two languages takes only about 35 seconds on a MacBook Air (M4 24GB). Even on a standard Windows PC, it can often be generated in under 5 minutes. Since "Gemma 4 E2B QAT" is compact, its processing speed is incredibly fast. It is well within practical levels for real-world use.

Explanation of Decision Basis and Model Accuracy (Malay)
3. The Quality of the Explanatory Text is Also Excellent
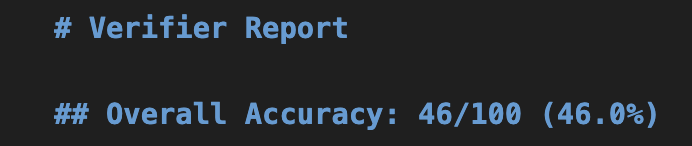
The most important point today is: "How accurate is the text generated by Gemma 4 E2B QAT?"
Small-scale generative AIs often lack the accumulated internal information compared to massive frontier models, so in my past experience, I frequently felt they were difficult to use practically in business. However, with "Gemma 4 E2B QAT," such worries were completely unnecessary. This app can output the prediction results as a PDF, so let's use that to take a closer look.

Here is the SHAP graph that served as the basis for the decision. We naturally want to explain this graph in easy-to-understand English, right?

Here is the explanatory text. What do you think? It's written in clear English, with absolutely no grammatical errors or spelling mistakes. I believe it provides a highly logical explanation based on the SHAP data above. When I first read it myself, I was actually a bit moved, thinking, "Can this little generative AI really do this much?"

So, what do you think? There are zero fees for using generative AI in this app. No invoices will be generated. You can use it freely for as many hours as you like. Isn't that fantastic!
Of course, "Gemma 4 E2B QAT" is not omnipotent, so it is necessary to use it strategically in combination with frontier models like Fable5 depending on the situation. However, I am beyond delighted that this ultra-compact generative AI has become a viable option. I feel we should actively use it while fully leveraging its major advantages: being entirely free and allowing highly confidential information to remain securely locked within your PC.
At Toshi Stats, we will continue to tackle tasks in the marketing field using the power of "Machine Learning + Generative AI." Stay tuned!
1) Gemma 4 QAT models: Optimizing model compression for mobile and laptop efficiency, 5 June 2026, Olivier Lacombe, Omar Sanseviero, Google DeepMind
2) Welcome to the SHAP documentation
Copyright © 2026 ToshiStats Co., Ltd. All right reserved.
Notice: This is for educational purpose only. ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the report, the codes and the software.