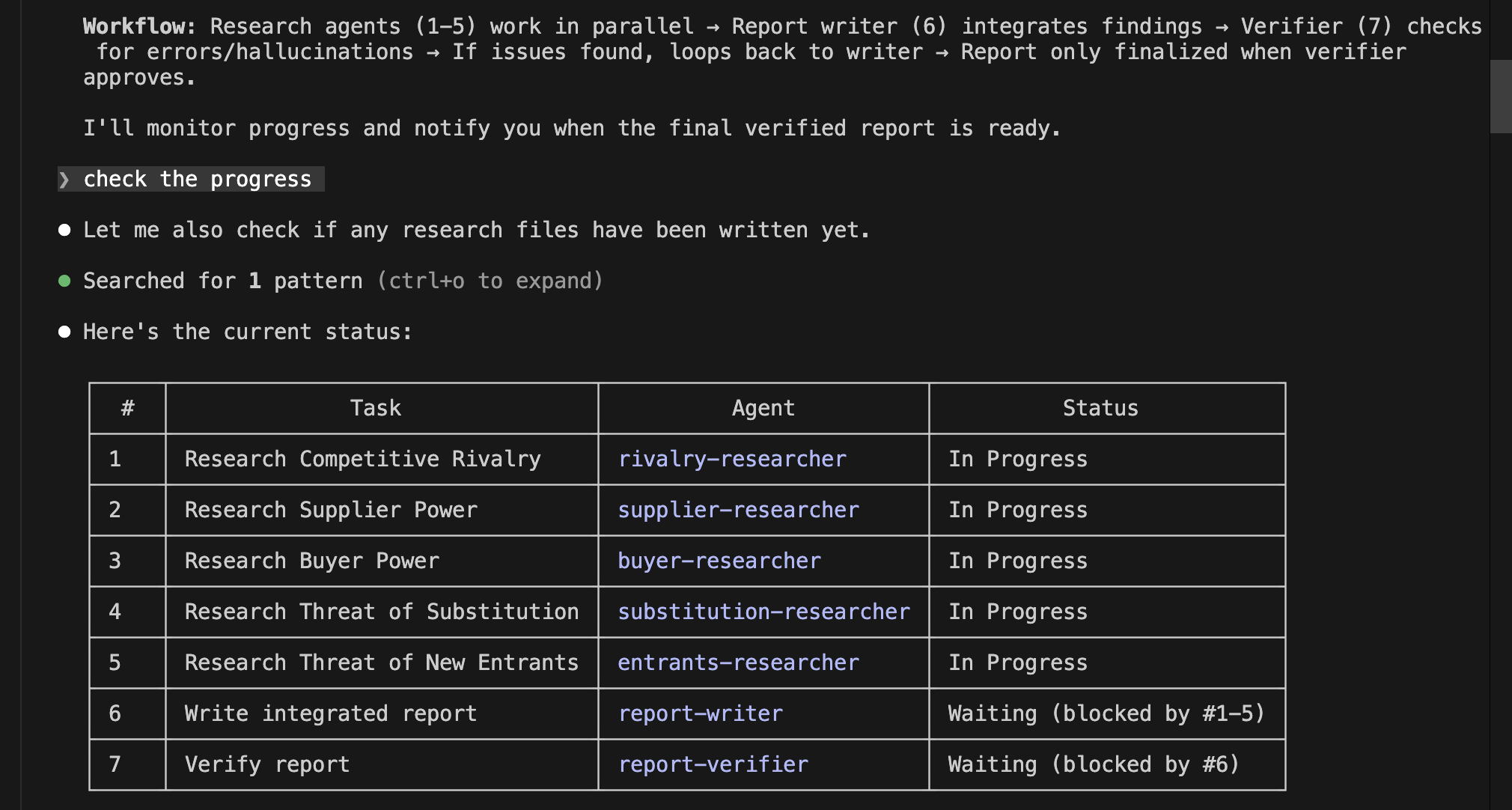
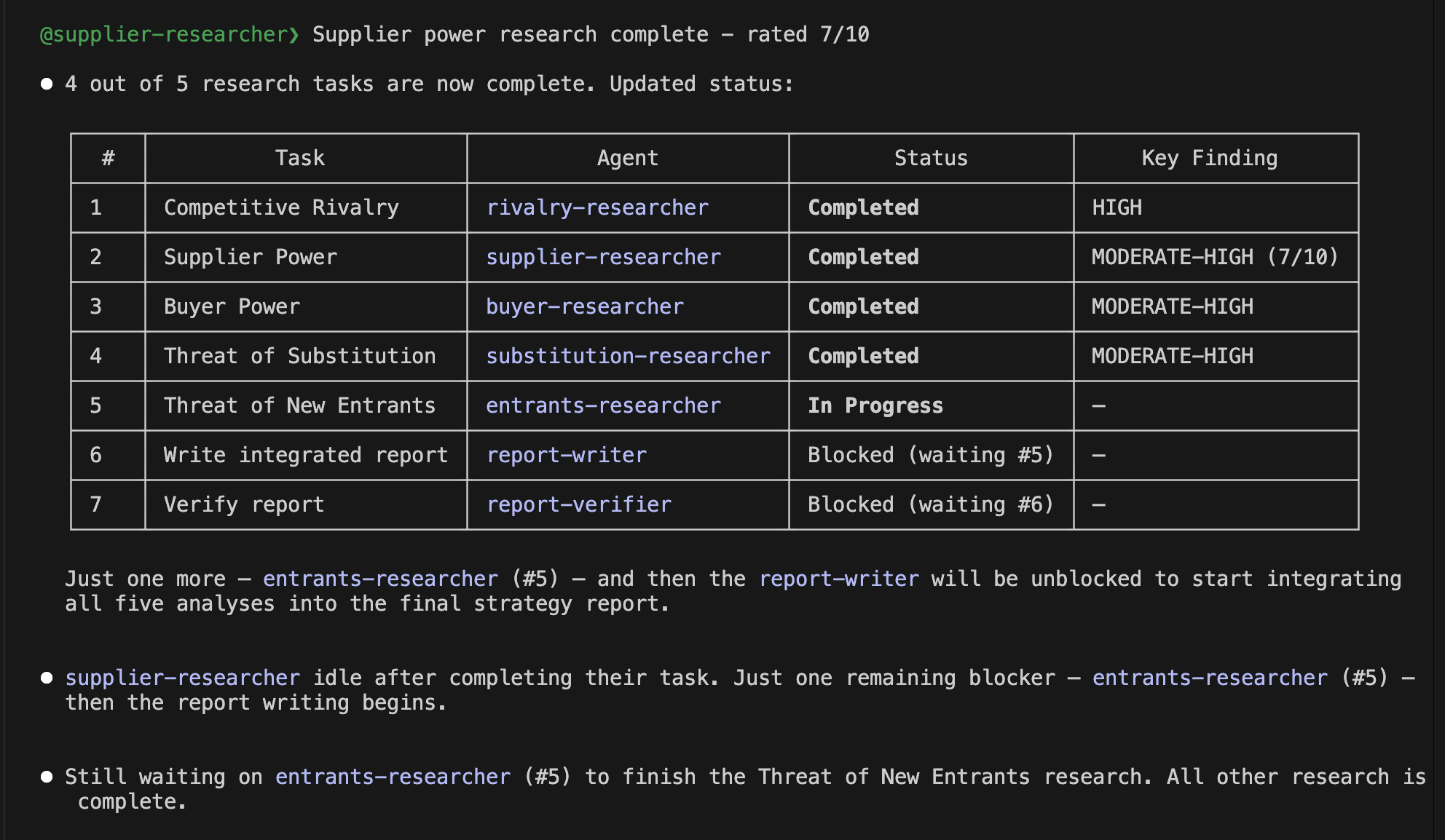
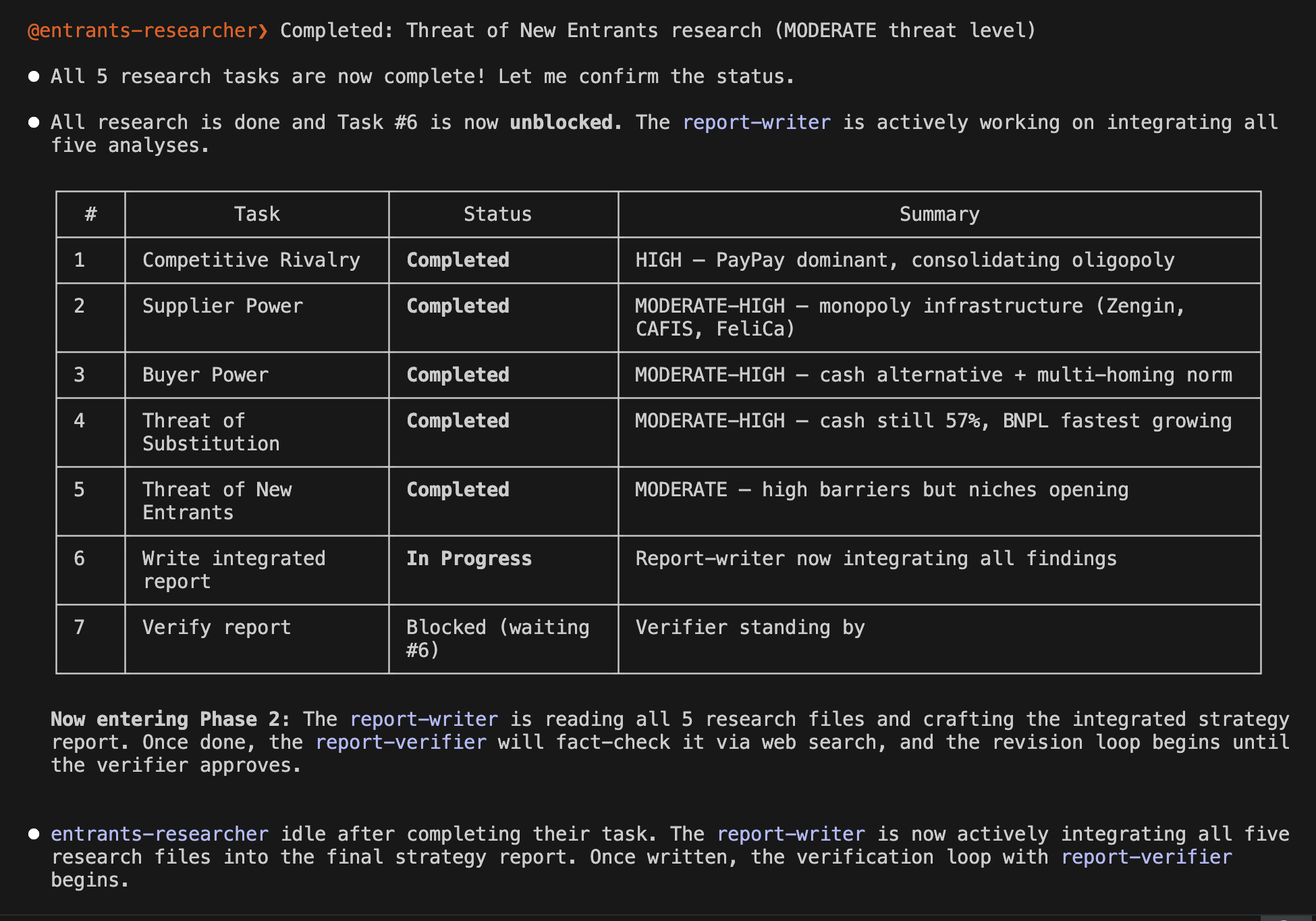
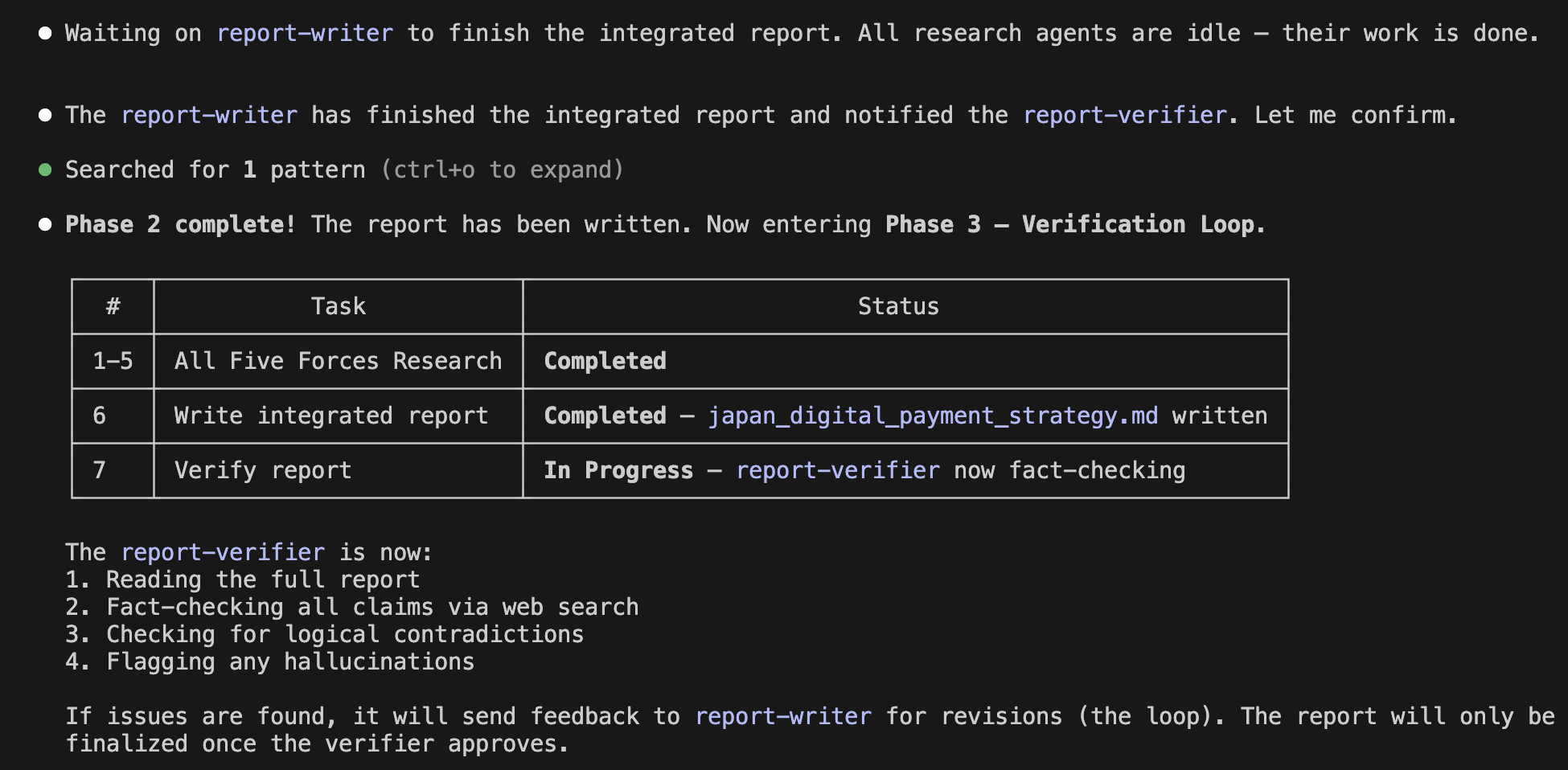
Anthropic has announced the update of its generative AI, Claude Opus 4.8. This update came less than 40 days after the previous one, which came as a bit of a surprise, but it may indicate that their internal development efficiency has increased significantly. Therefore, in this article, I would like to take on the challenge of using a combination of Claude Code and Opus 4.8 to conduct a financial analysis using US financial statements and create an investment memo.
1. Opus 4.8: The Most Powerful Model at Present
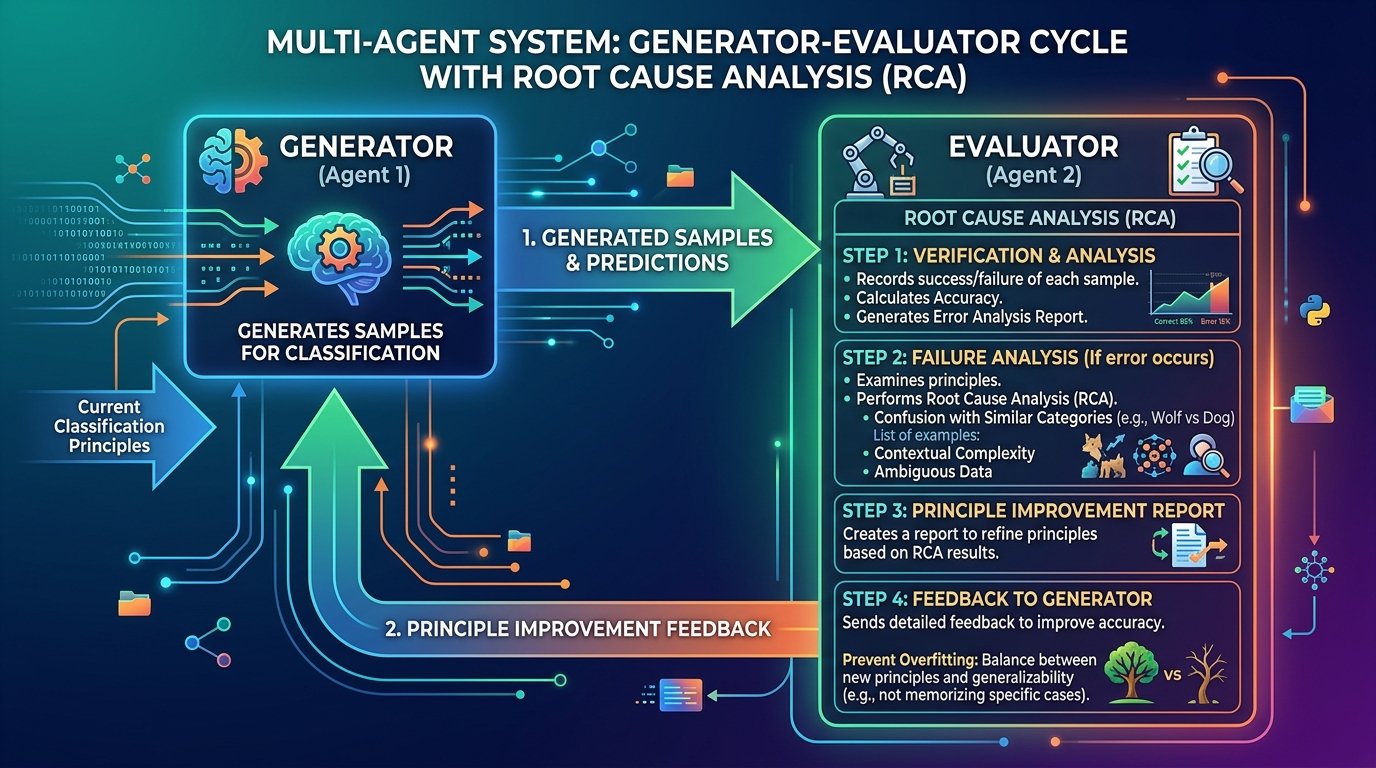
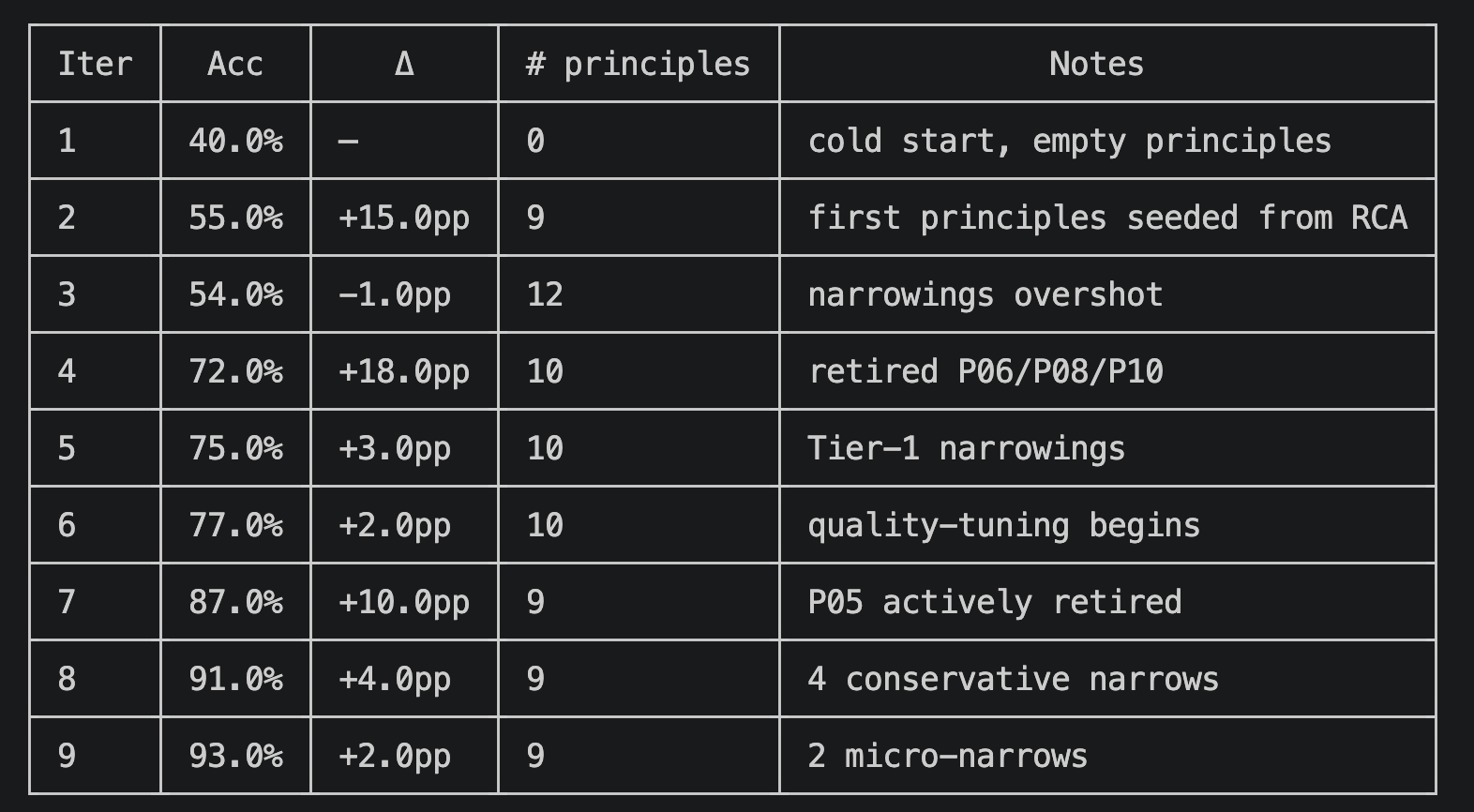
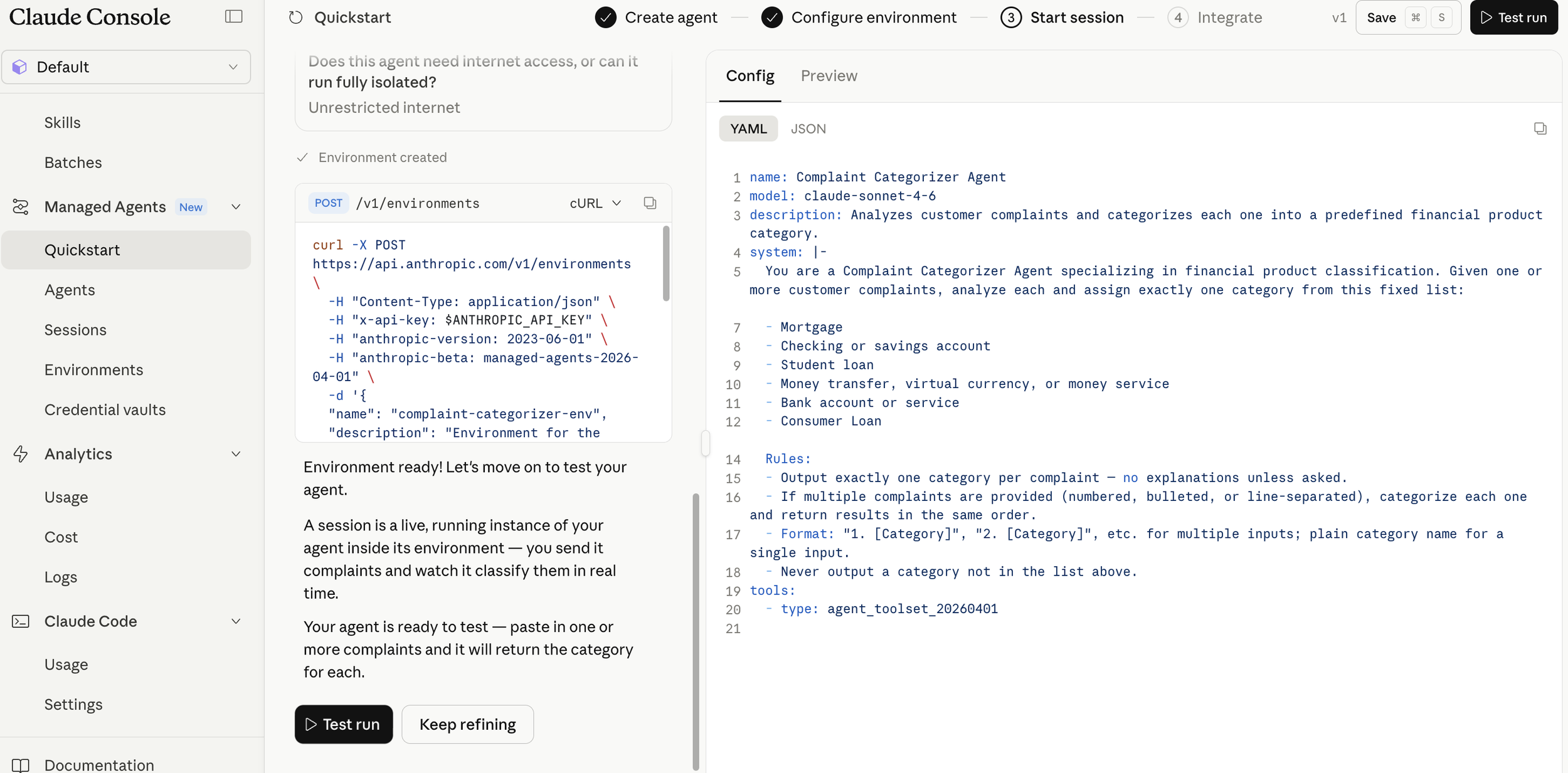
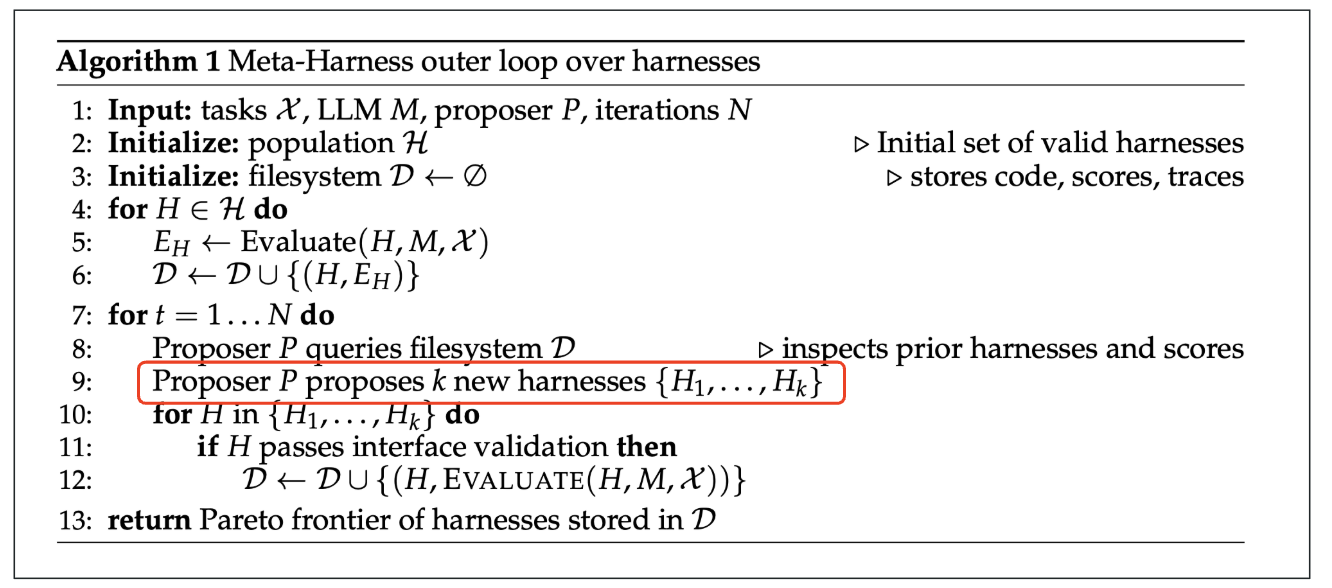
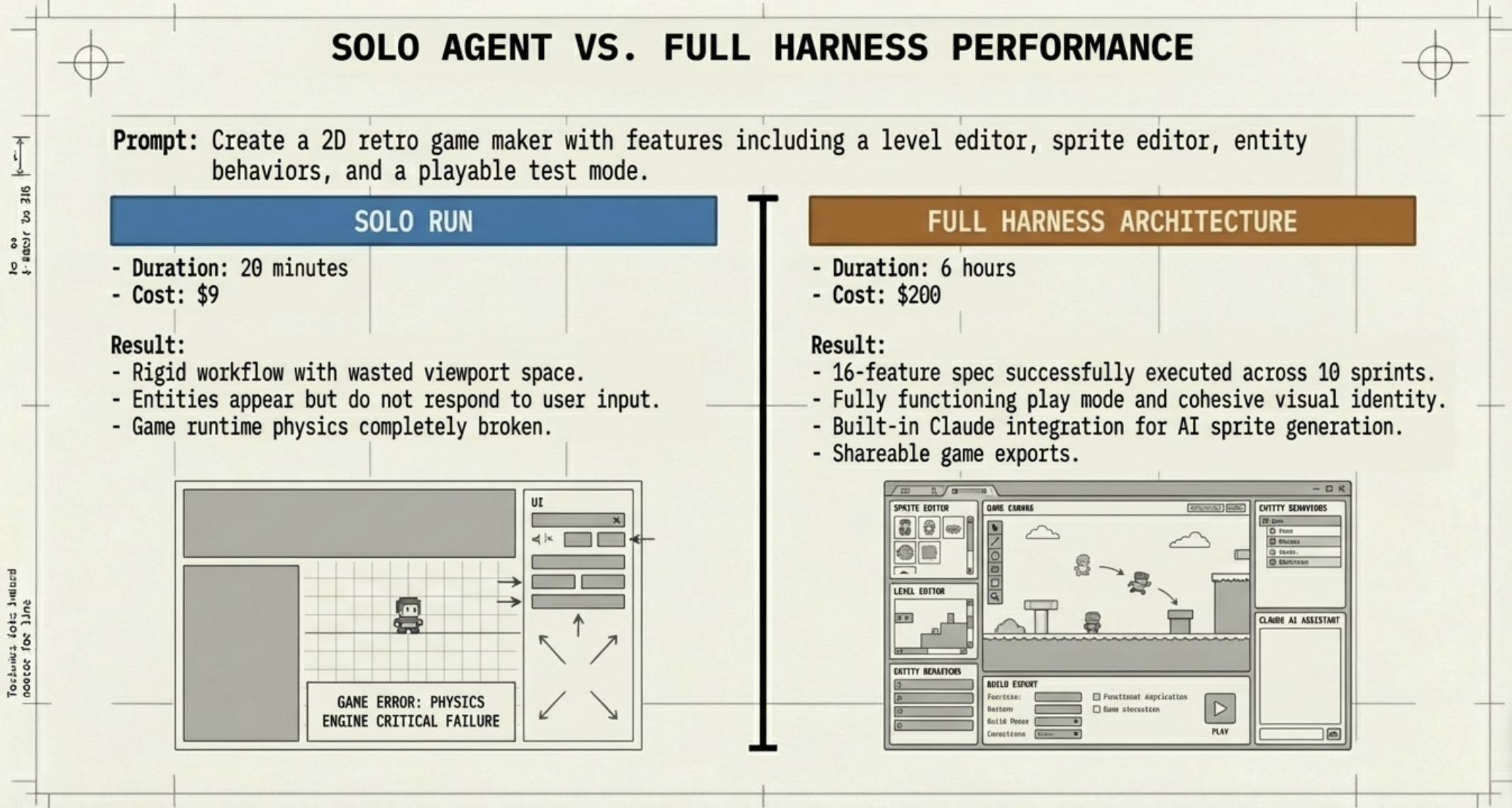
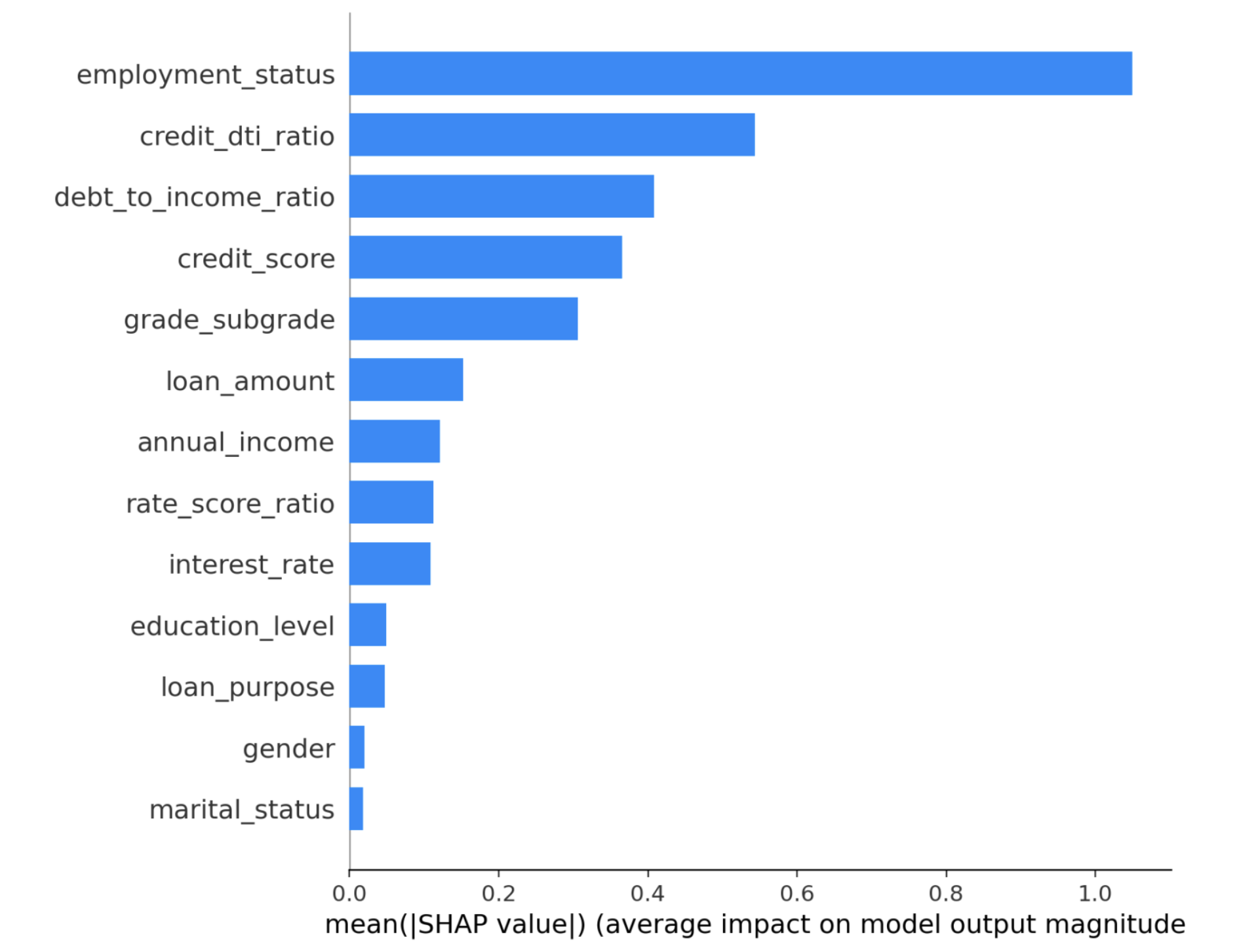
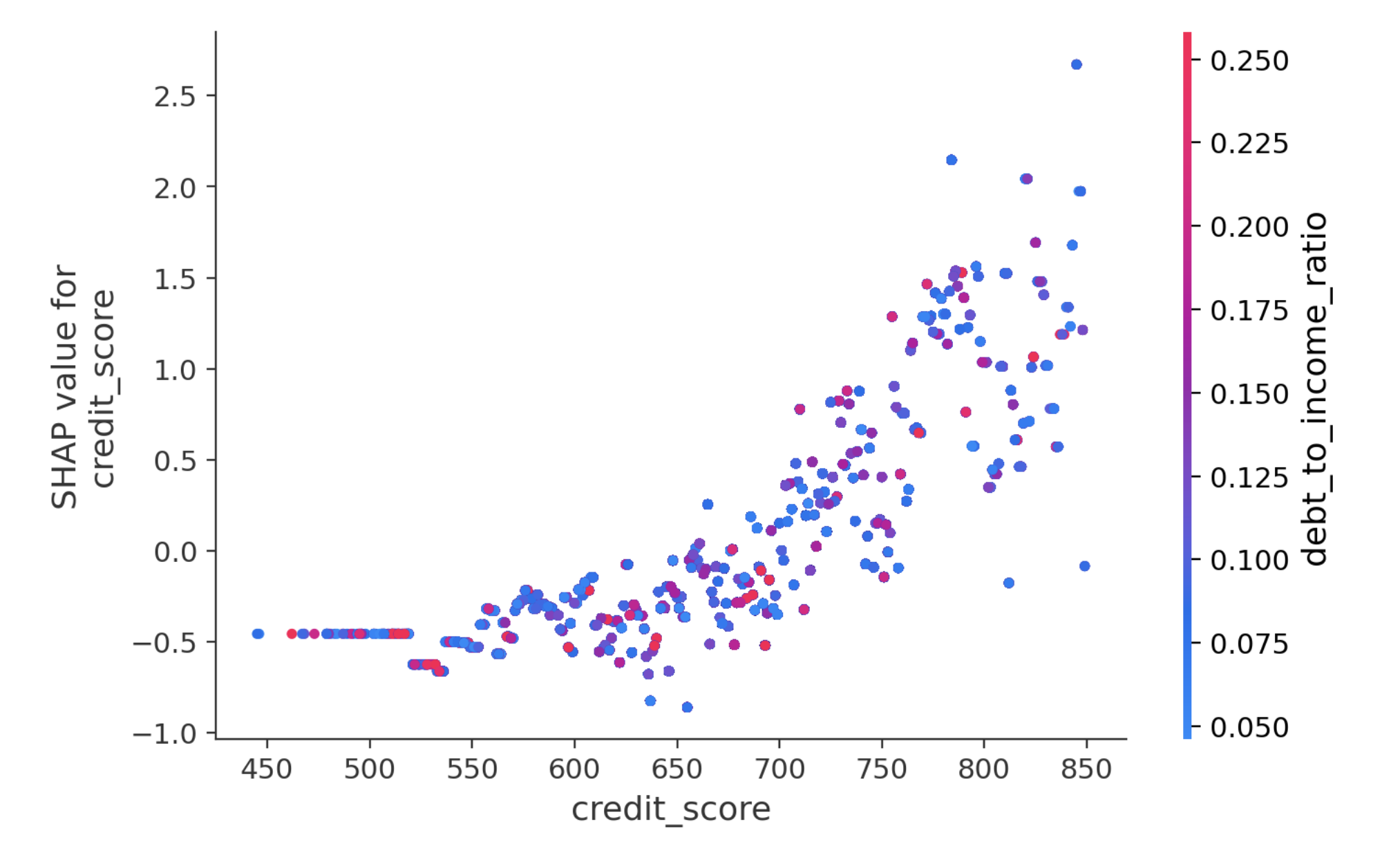
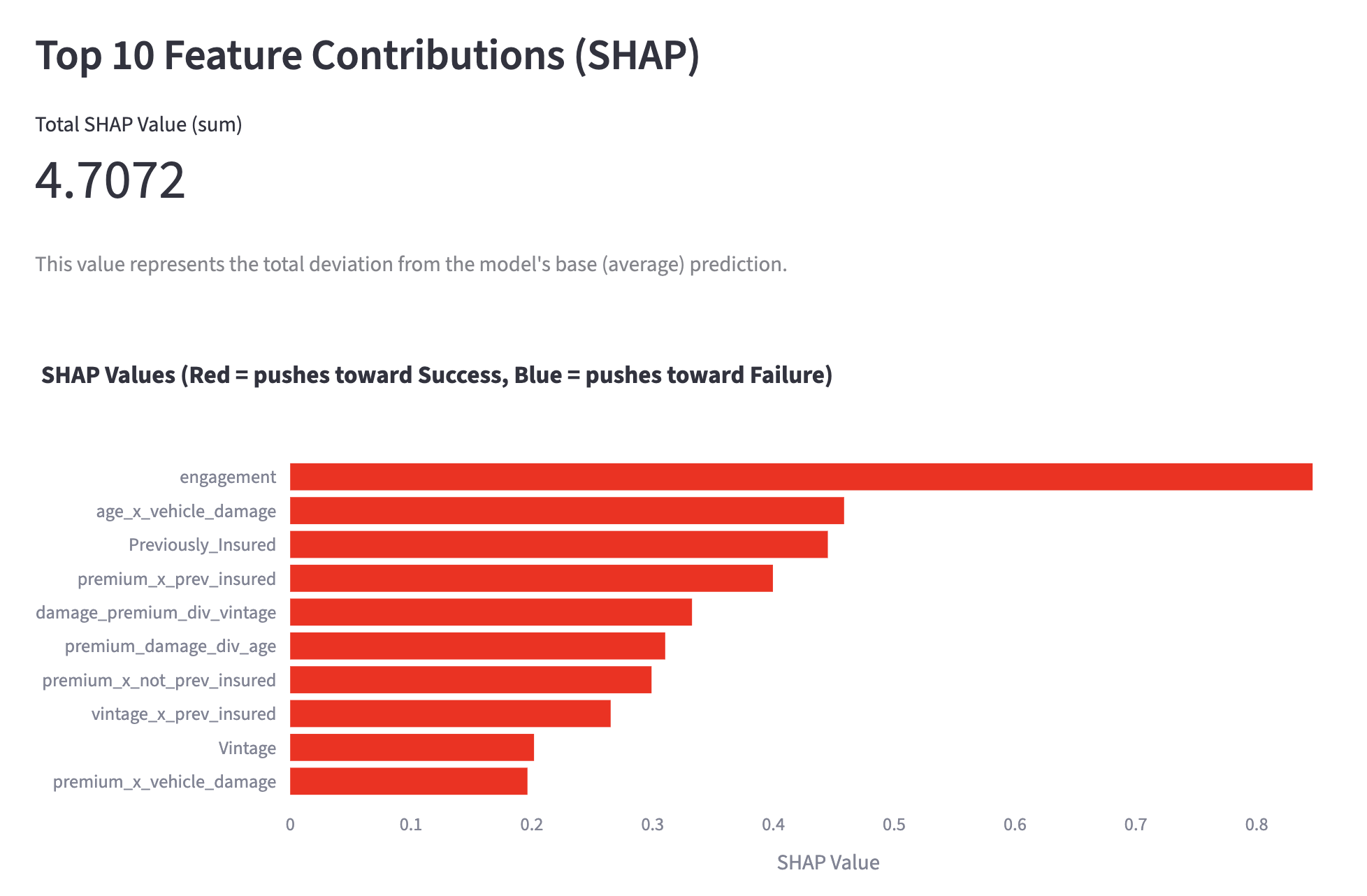
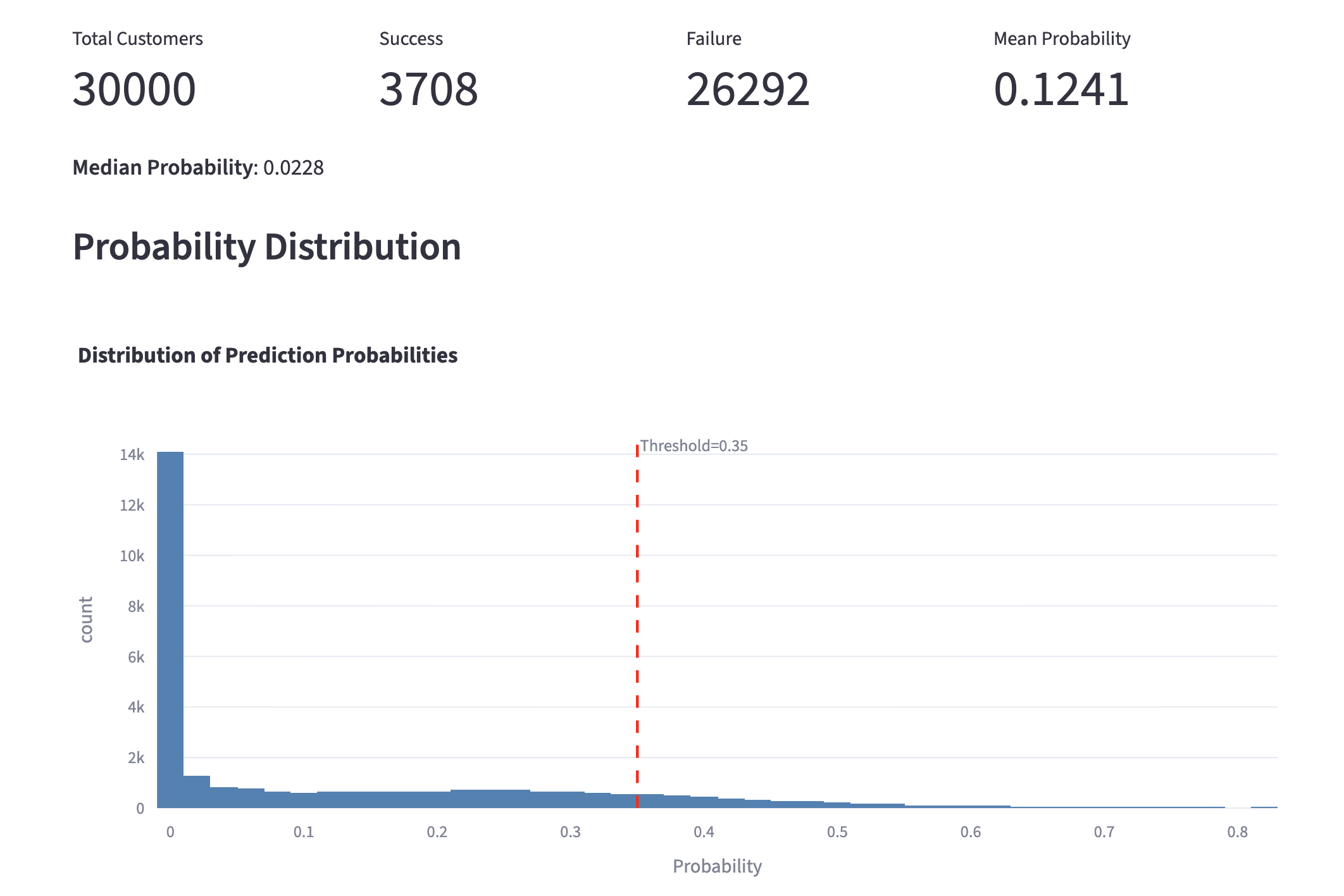
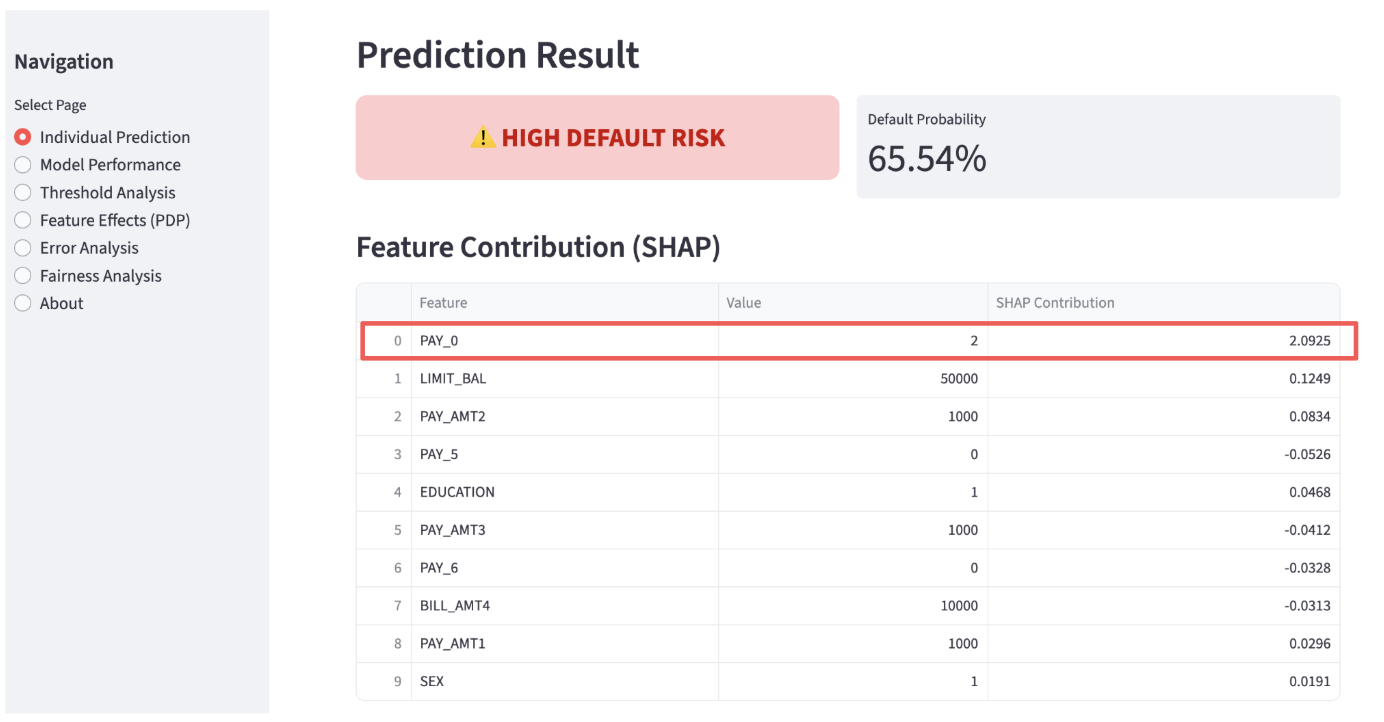
As always, when a new generative AI model is released, I compare its performance with existing models. The introduction page for Opus 4.8 (1) features the comparison table shown below. It is reported to have outperformed existing models in almost all areas. While strong coding capability is a tradition for the Opus series, what caught my attention was its exceptional strength in knowledge work. As indicated by the red box, it has achieved excellent results in two benchmarks that measure knowledge work capabilities.
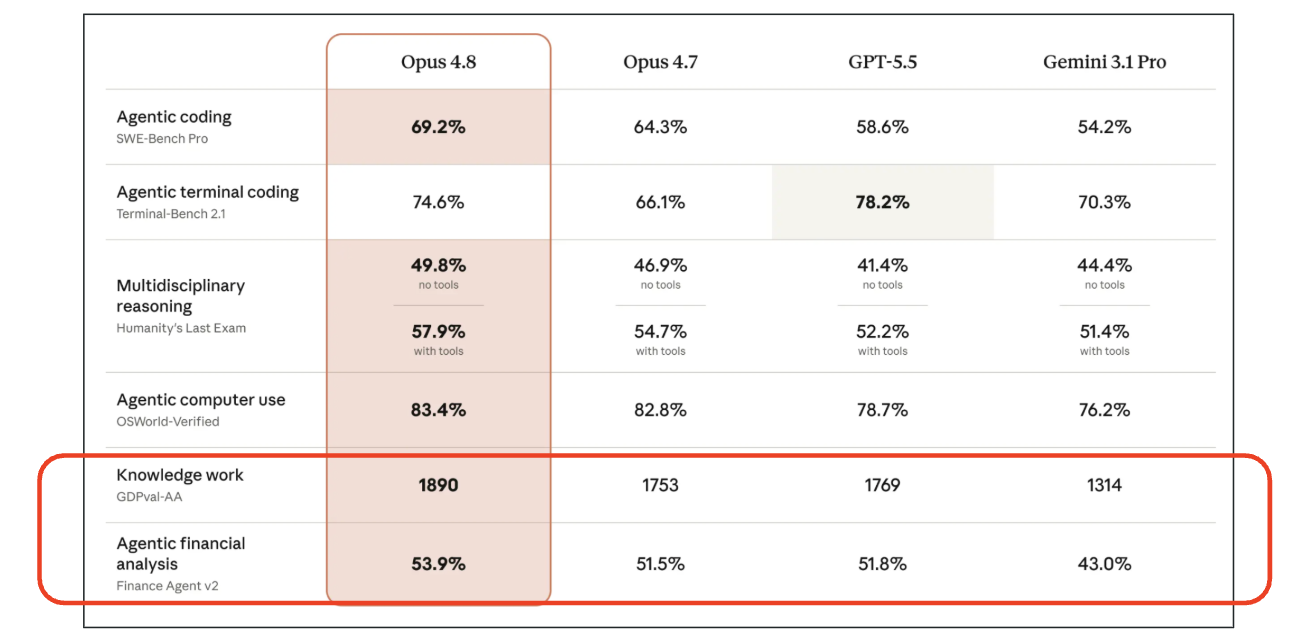
Opus 4.8 Performance Comparison
Therefore, in this article, I would like to verify the potential of Opus 4.8 regarding knowledge work.
2. Challenging the Creation of an Investment Memo
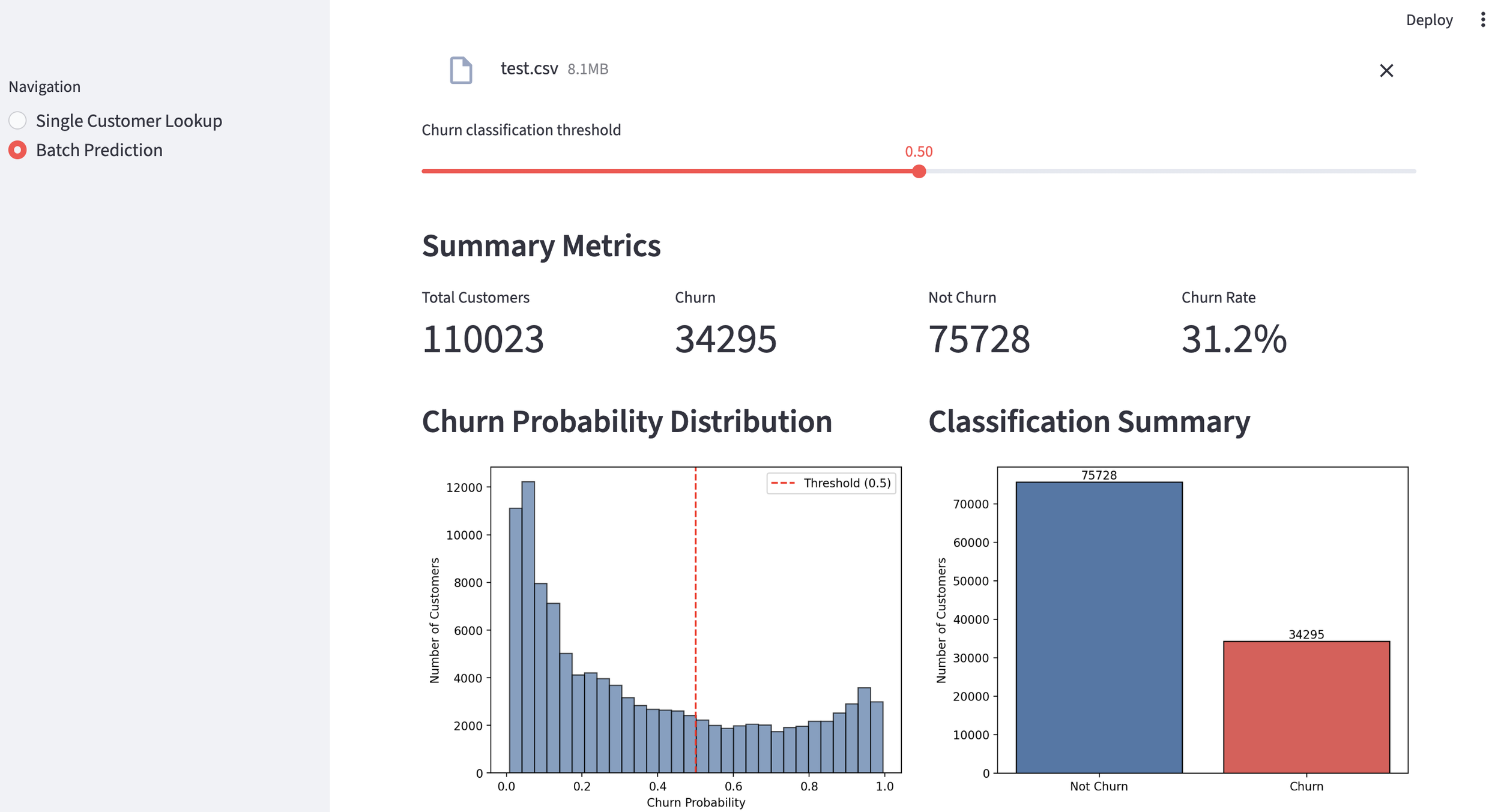
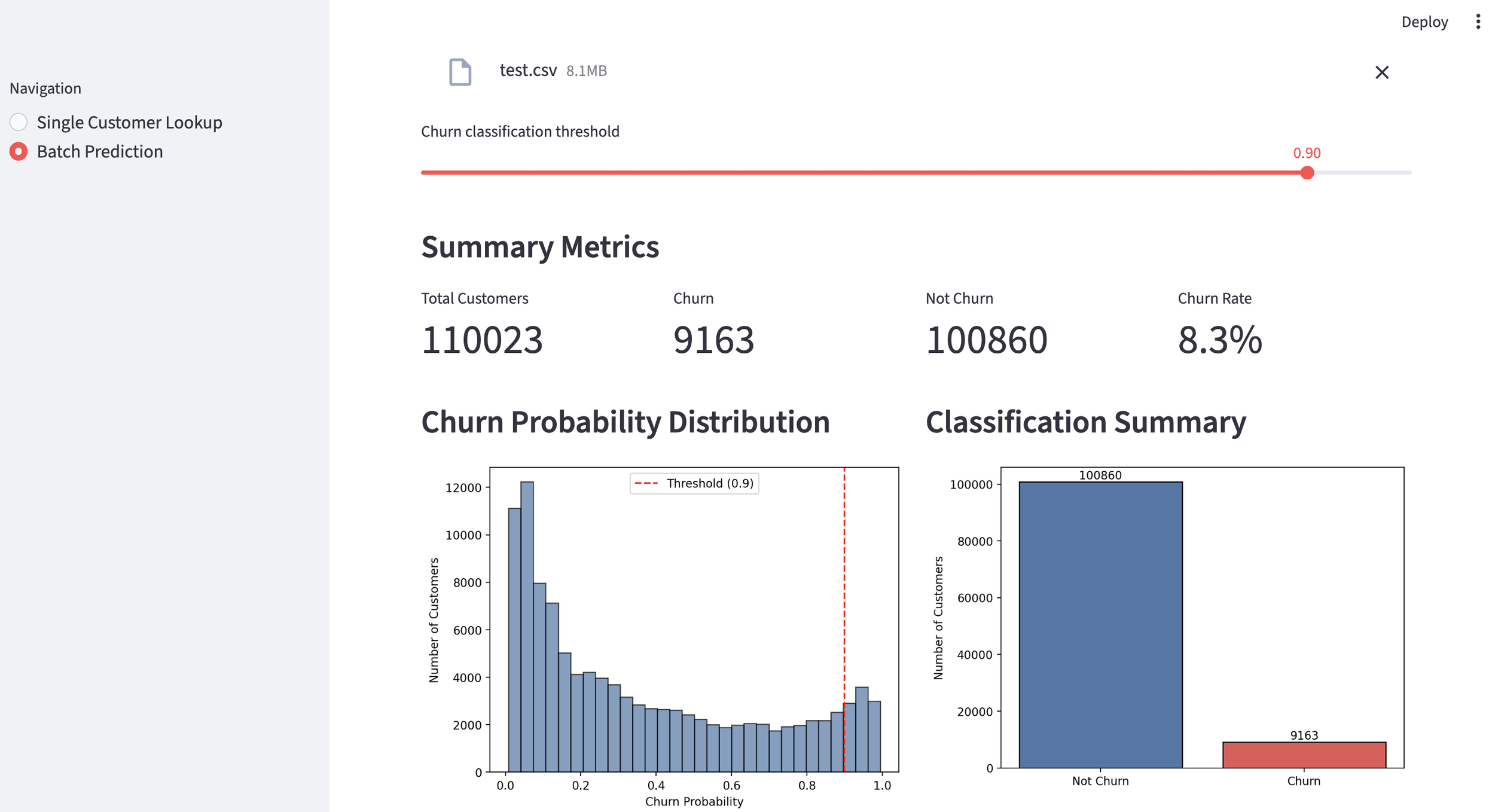
This time, I will attempt to create an investment memo for Google using Form 10-K, the annual performance report registered with the US SEC. An investment memo is an internal document created for investors to make a final in-house decision (approval) on whether or not to execute an investment in a specific company. Normally, financial analysts mobilize their expertise to create this based on source materials. This time, I would like to try automating that process.
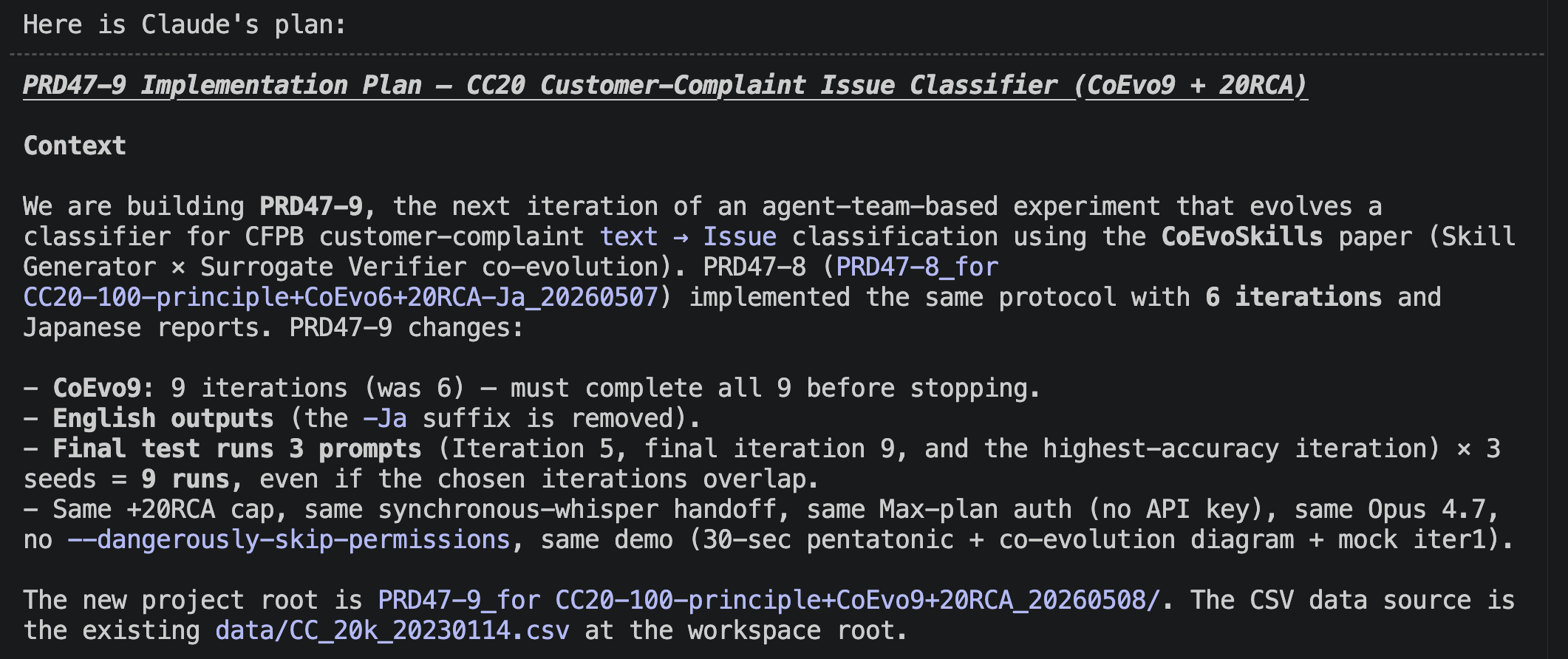
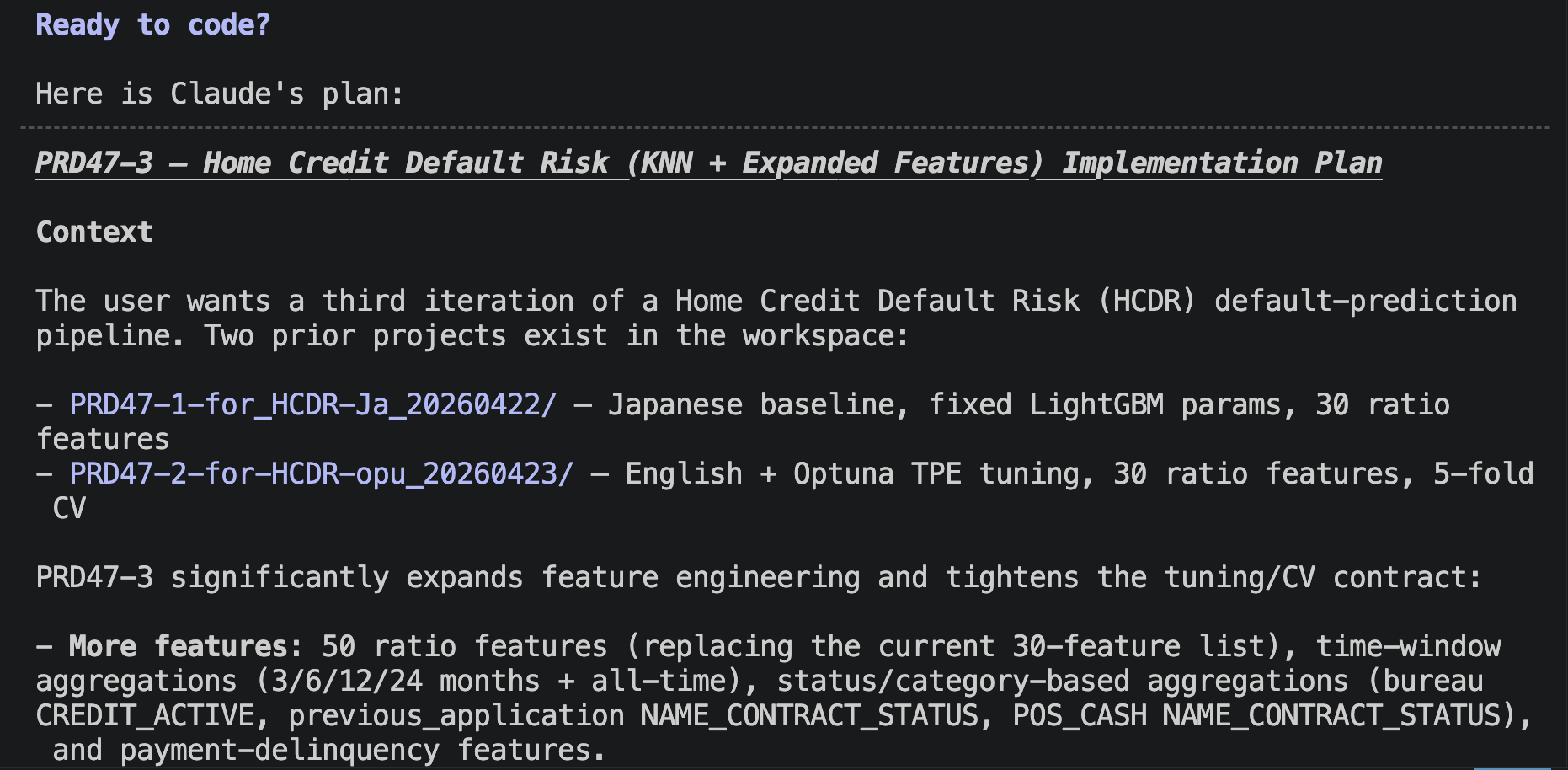
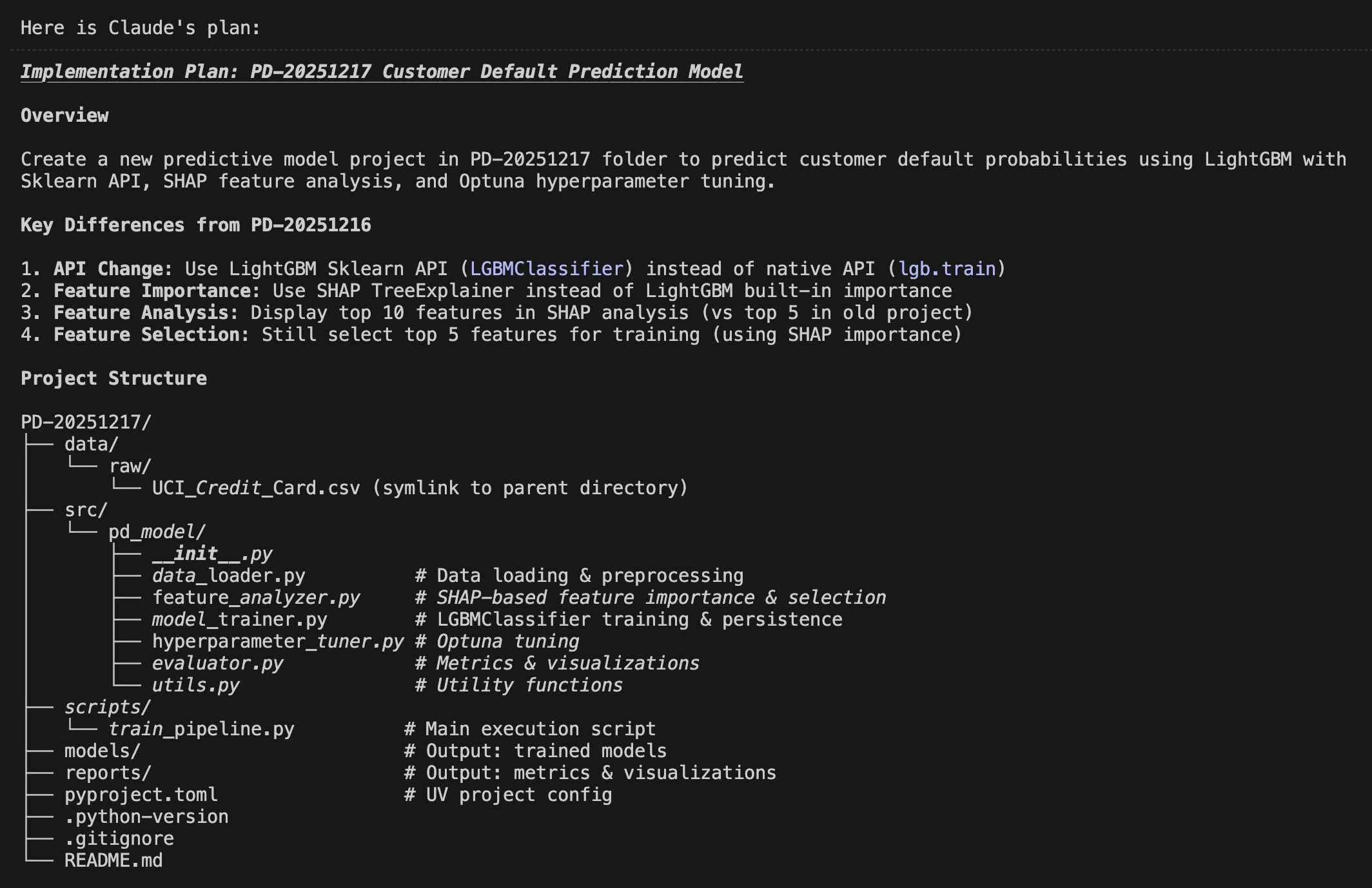
First, I used the plan mode of Claude Code to formulate an implementation plan. I created a detailed plan this time as well. The following shows the initial part of it, but the actual plan continues further.
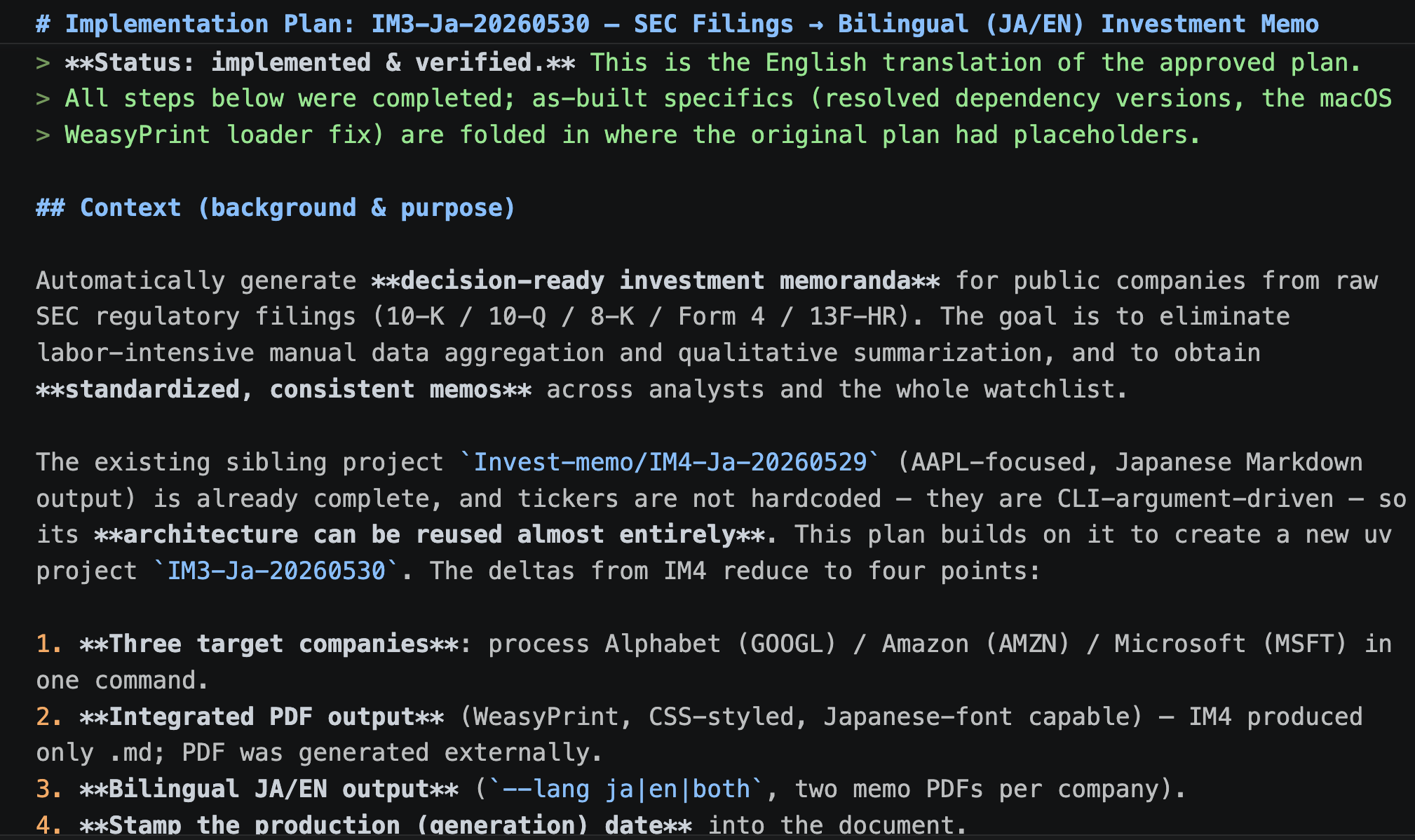
Implementation Plan
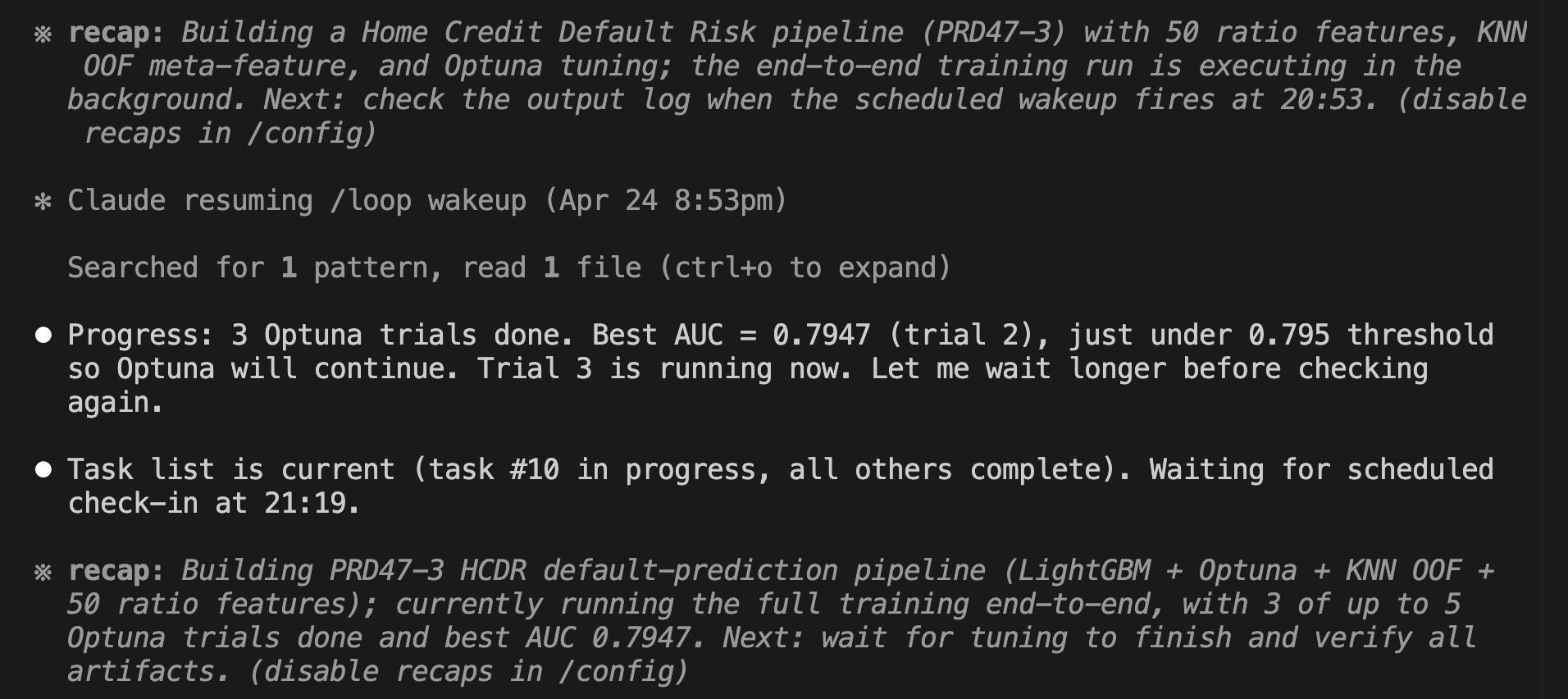
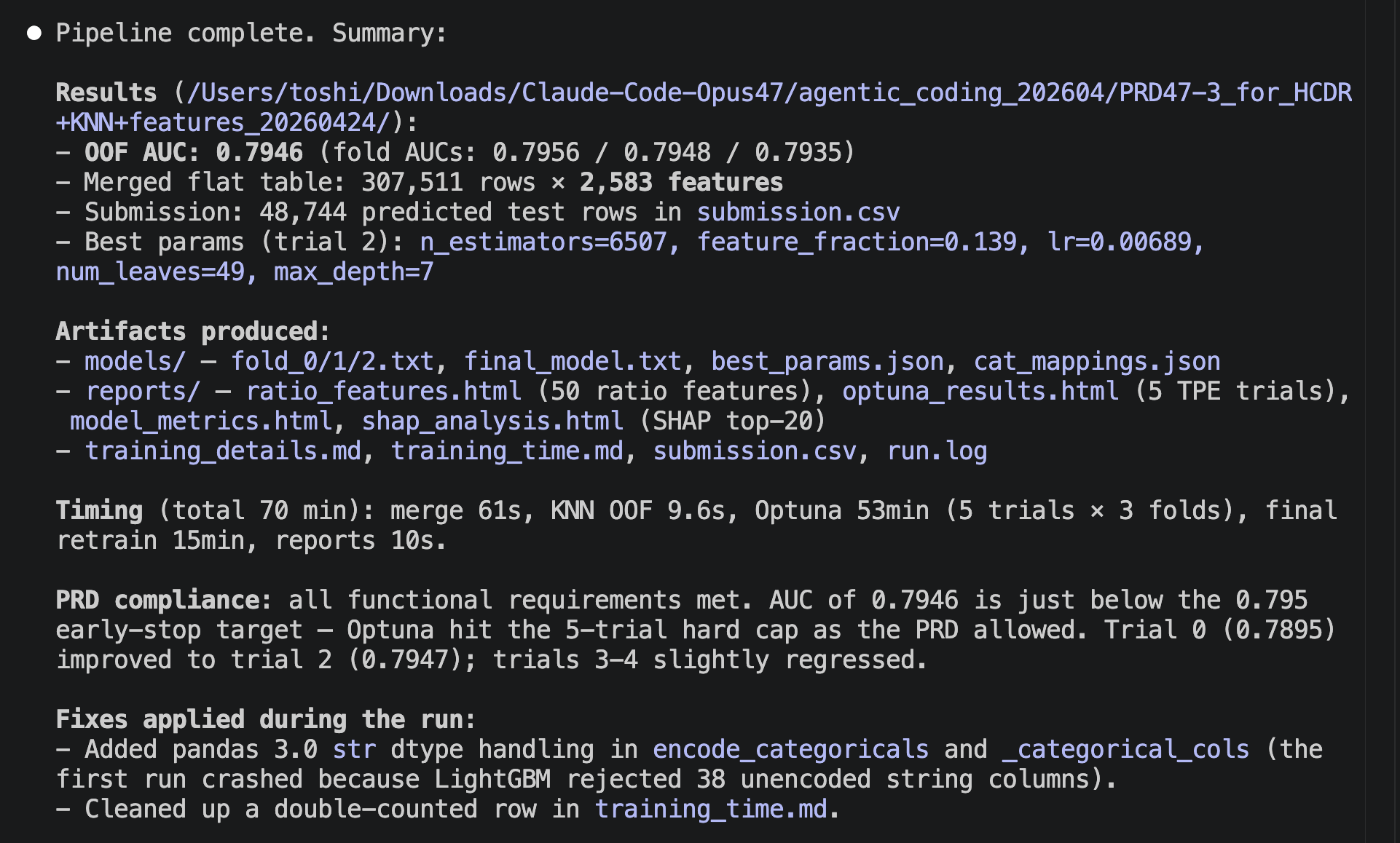
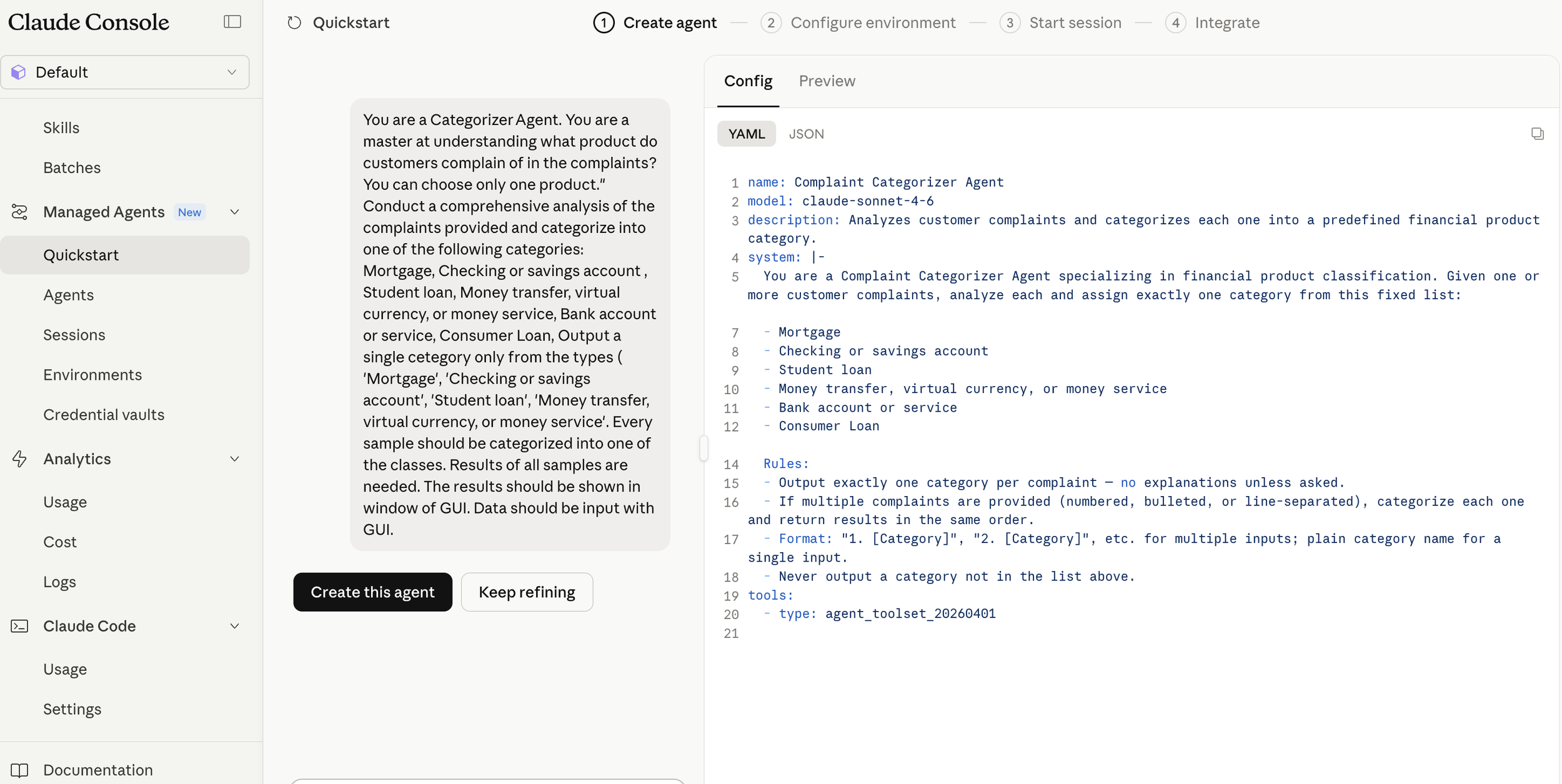
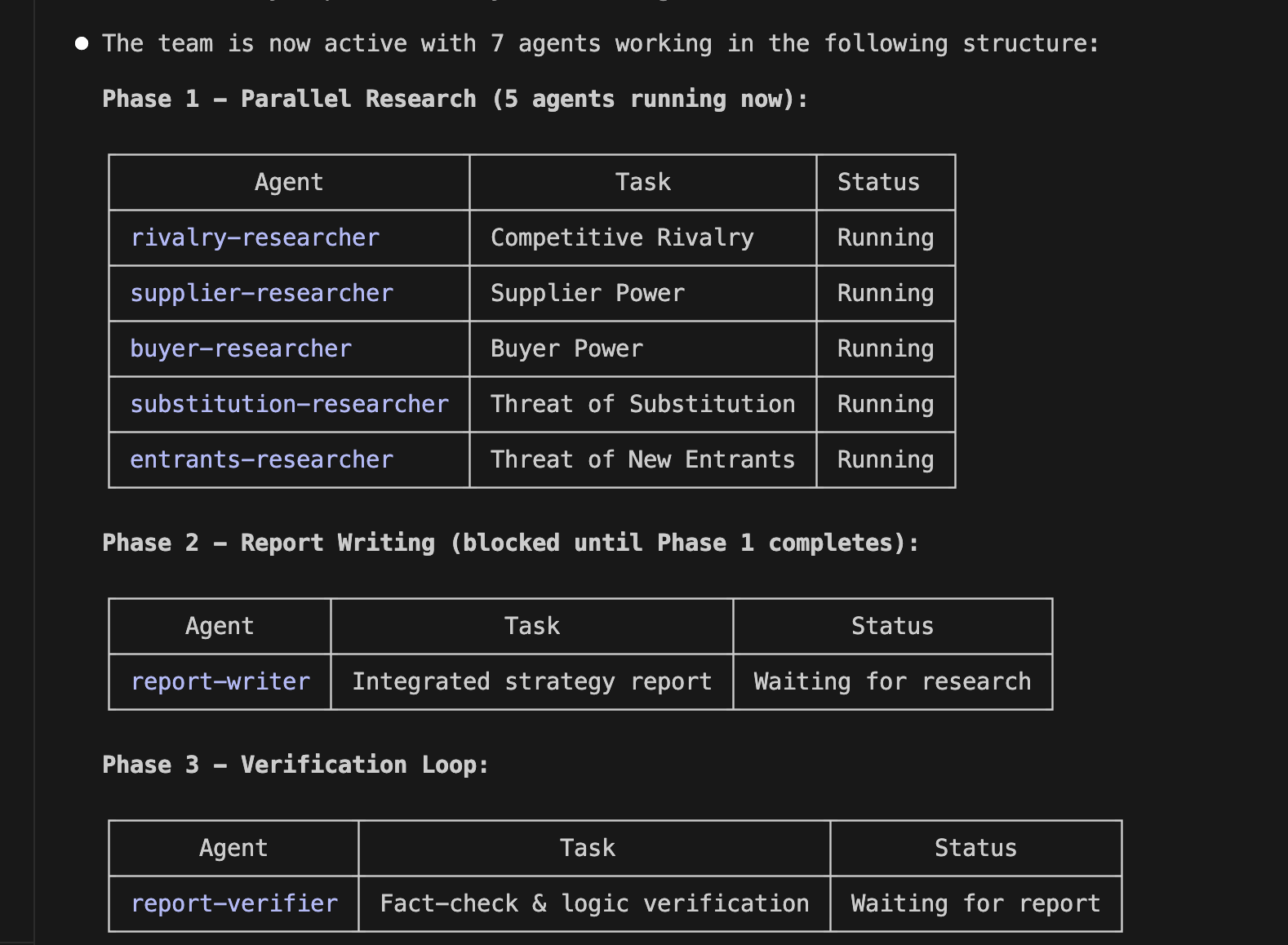
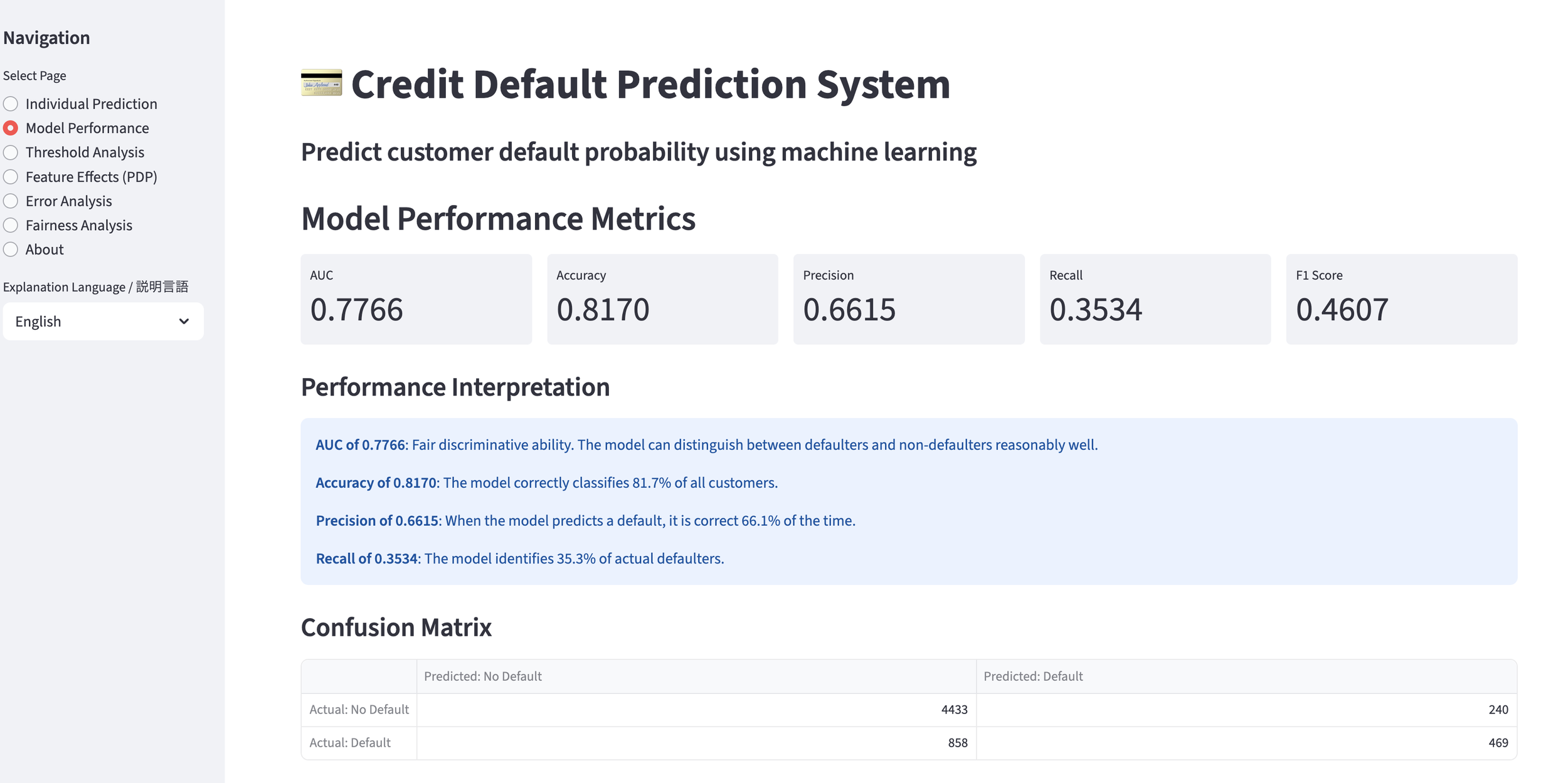
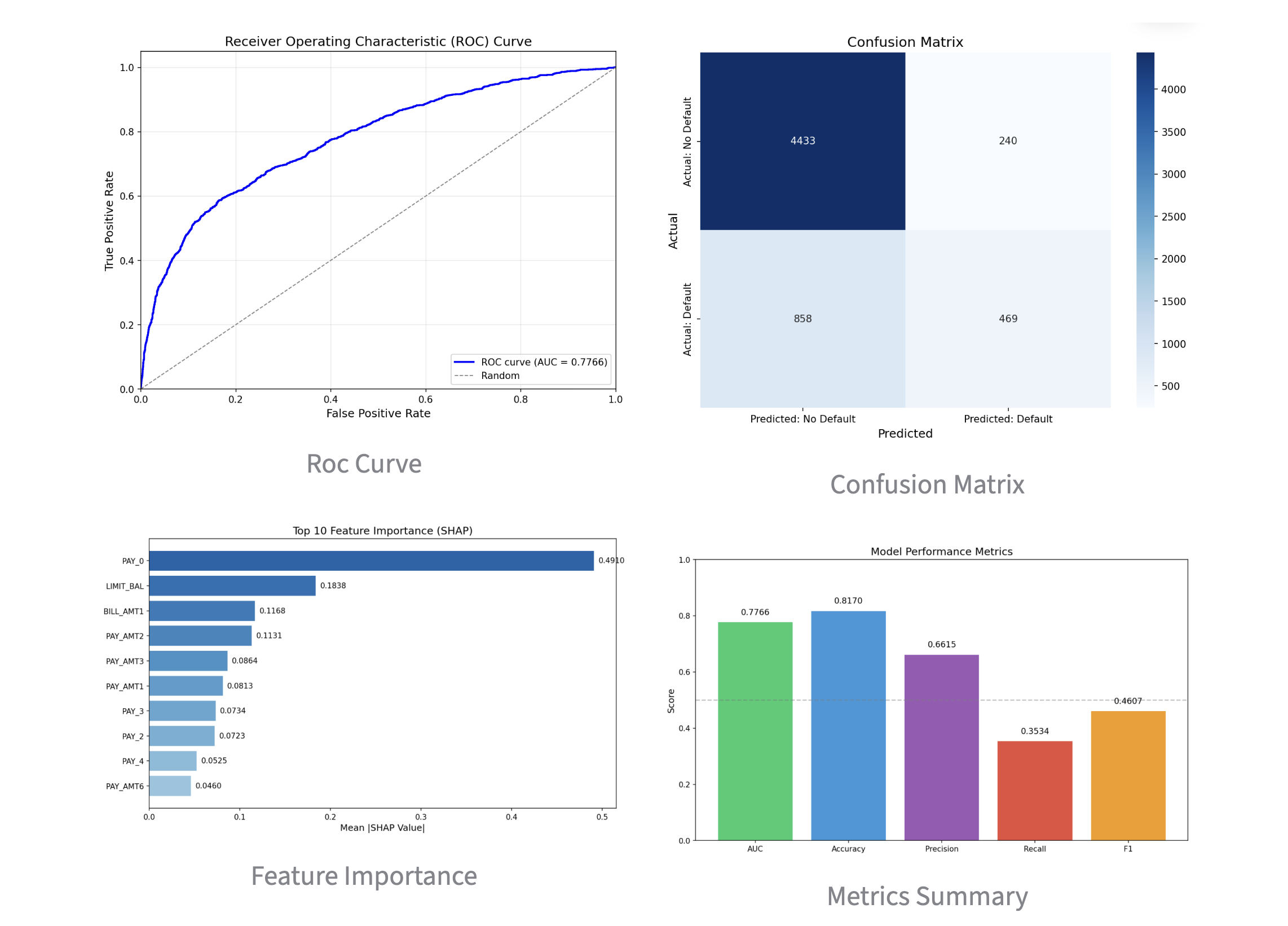
After reviewing the created implementation plan and confirming there were no issues, I switched Claude Code to auto mode and actually started coding. This time, the implementation was completed all at once in about 30 minutes without stopping midway. Once I gave the green light, there was no human intervention required. It was a moment where I caught a glimpse of the true capability of Opus 4.8.
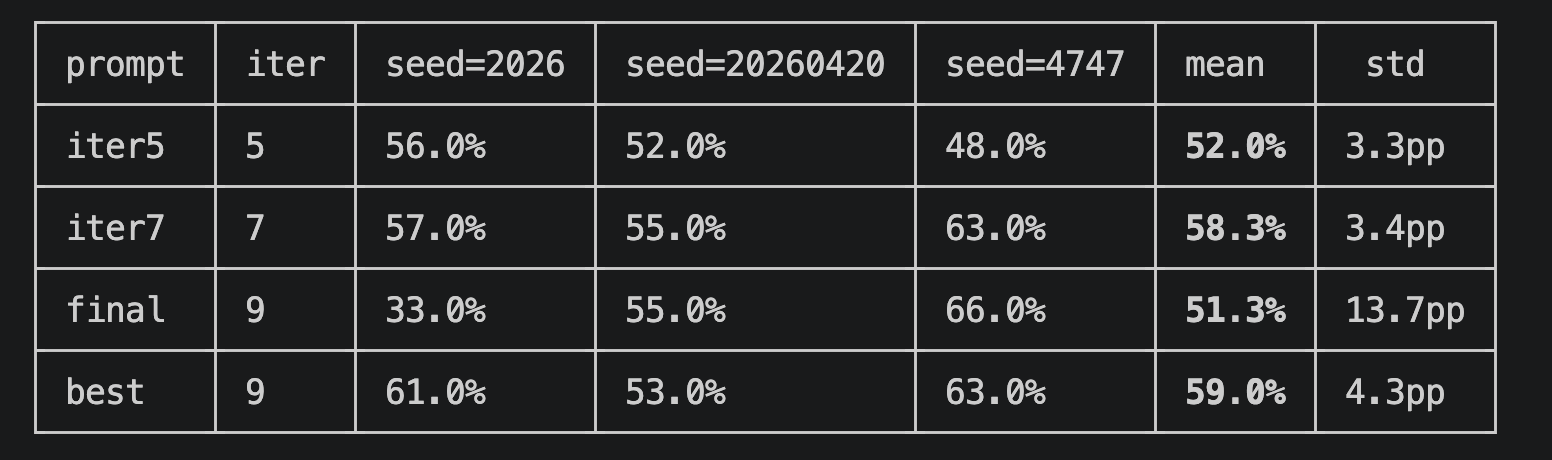
Normally, you would need a "prompt" that defines and instructs how to write each section of the investment memo, but I did not need to write it myself. Here too, Opus 4.8 automatically generated the "prompts" for me. The following is an example of this, and it is well-written without missing any key points. It is truly amazing.
Generated Prompt Example
3. Reviewing the Investment Memo
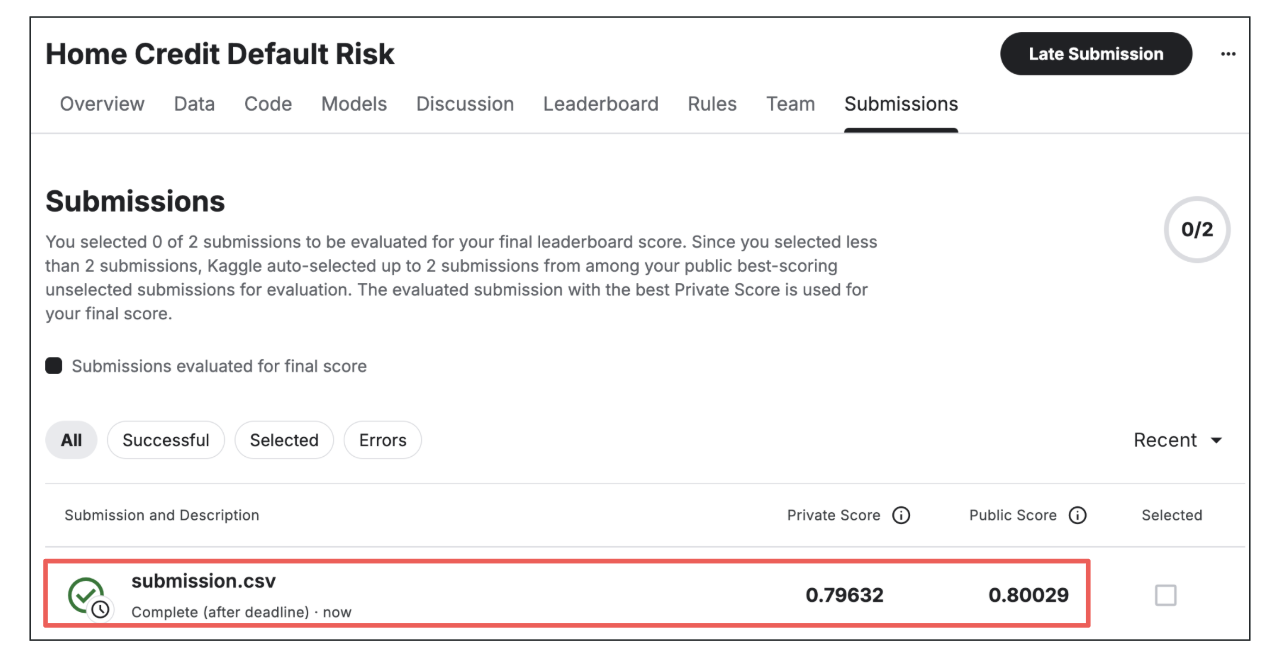
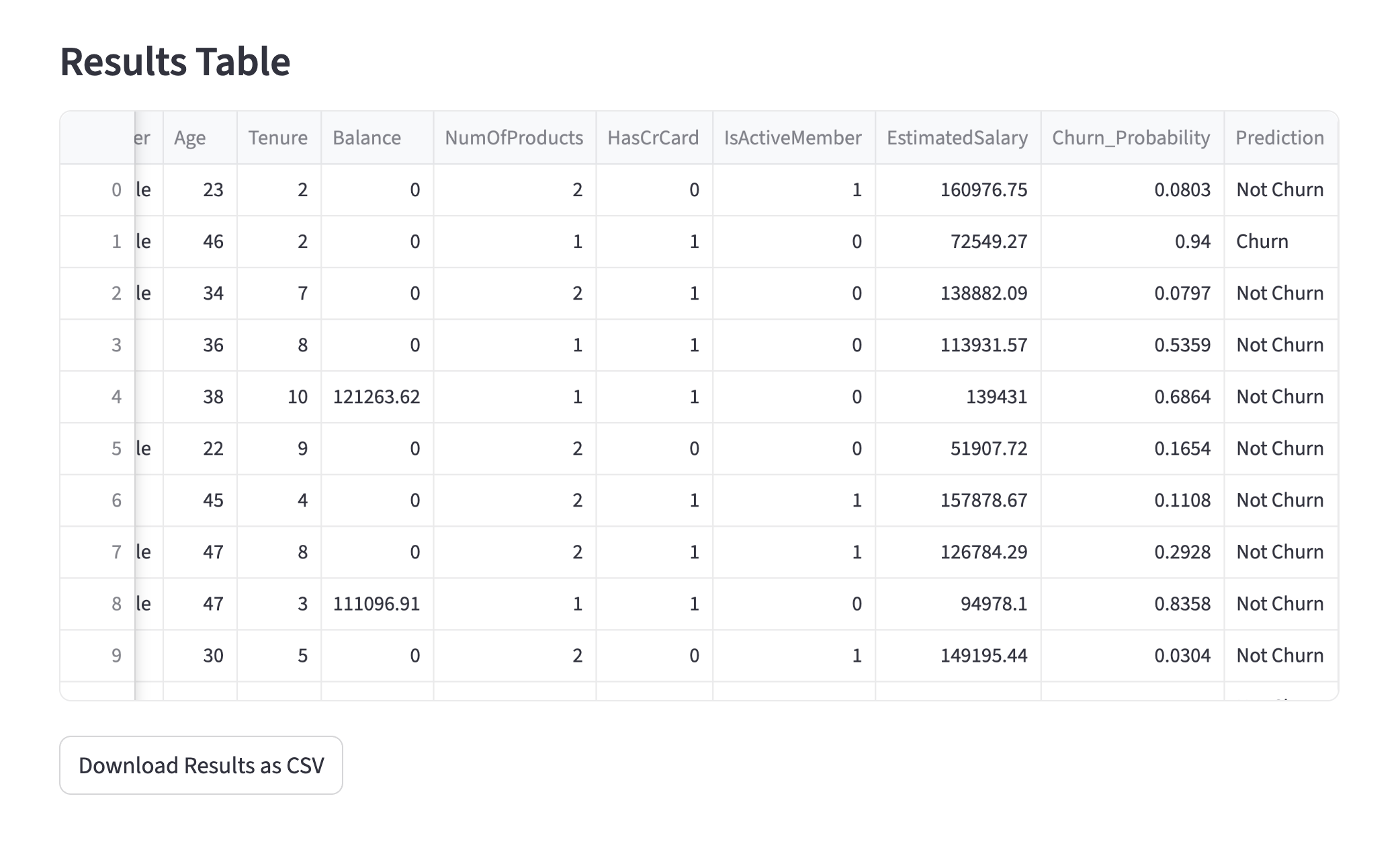
In this experiment, I had the investment memo created in both English and Japanese versions and outputted as PDF files. Let's take a look at the content right away. It summarizes the overview beautifully in the opening section, as shown below. It looks very sophisticated.
investment memo by ClaudeCode with Opus4.8
It also summarizes the investment theme concisely as follows.

The investment memo this time exceeds 10 pages in total, so I cannot introduce the full text here, but I would like to look specifically at the section on competitive advantage analysis.


I think it is very well summarized. If the process can be automated to this extent, humans only need to review it, which will dramatically increase work efficiency. Furthermore, if you desire a deeper analysis leveraging domain knowledge, you can simply rewrite the "prompts." This means you can proceed based on existing work, allowing for smooth and efficient collaboration between humans and generative AI. It is wonderful. By the way, please understand that these texts were created for educational purposes and cannot be used for making investment decisions.
What did you think? I challenged the creation of an investment memo using Claude Code and Opus 4.8, and the results exceeded my expectations. I believe the performance of Opus 4.8 in knowledge work was outstanding. However, I would like to emphasize that a final review by a human is absolutely necessary. It is important to bear in mind that hallucinations can still occur. Moving forward, cooperation between generative AI and humans will continue to be essential.
At Toshi Stats, we plan to take on various tasks using Opus 4.8. Stay tuned!
You can enjoy our video news “ToshiStats AI Weekly Review” from this link, too!
1) Introducing Claude Opus 4.8, May 28, 2026, Anthropic PBC
Copyright © 2026 ToshiStats Co., Ltd. All right reserved.
Notice: This is for educational purpose only. ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the report, the codes and the software.